Python 内存管理策略
引用计数、垃圾回收、内存池机制
垃圾回收机制主要是以引用计数为主要手段以标记清除和隔代回收机制为辅的手段
引用计数(reference count)
在python中,每个对象都有存有该对象的引用总数,即引用计数。
每个对象维护一个 ob_ref,用来记录该对象当前被引用的次数,一旦对象的引用计数为0,该对象可以被回收,对象占用的内存空间将被释放。
它的缺点是需要额外的空间维护计数,这个问题是其次的,最主要的问题是它不能解决对象的“循环引用”【闭包】。
增加情形
- 对象被创建:x = [1] [1]为对象
- 新增其他别名对其引用:y = x 变量名为别名
- 被作为参数传递给函数:foo(x)
- 作为容器对象的一个元素:a = [x]
from sys import getrefcount # 这里指代的是别名(变量名)指向的对象的引用
# &1
x = [1] # 这里如果赋值如 1,则可能涉及到 Python 的内存池机制,返回的是 120,其他数字不等,如 2 为 94,3 为 31,0 为 251;而直接对数字 getrefcount(num) 又会比赋值后 getrefcount(x) 大 2
# &3
print(getrefcount(x)) # 返回 2,包括了传入该方法的引用
# &2
y = x
print(getrefcount(x)) # 返回 3,包括了传入该方法的引用
print(getrefcount(y)) # 返回 3,包括了传入该方法的引用
# &4
z = [x]
print(getrefcount(x)) # 返回 4,包括了传入该方法的引用
print(getrefcount(y)) # 返回 4,包括了传入该方法的引用
print(getrefcount(z)) # 返回 2,包括了传入该方法的引用减少情形
- 一个本地引用或对象离开了它的作用域。如函数 foo(x) 结束时,x 指向的对象引用减一
- 对象别名被显式销毁:del x
- 对象的一个别名赋值给了其他对象:x = 666
- 对象从另一个容器对象中移除:z.remove(x)
- 容器对象本身被销毁:del z
# 接上 x -> 4 | y -> 4 | z -> 2,包括调用 getrefcount 时的 1 次引用
# &3
# 不可赋值太小,因为有 Python 小数据内存池机制 -5~257
x = 666 # x -> 2 | y -> 3 | z -> 2
# &4
del z # x -> 2 | y -> 2 | z -> 0
x = [1]
y = x # # x -> 0 | y -> 3 | z -> 2
# &2
del x # x -> 0 | y -> 2 | z -> 2垃圾回收
当内存中有不再使用的部分时,垃圾收集器就会把他们清理掉。它会去检查那些引用计数为0的对象,然后清除其在内存的空间。当然除了引用计数为0的会被清除,还有一种情况也会被垃圾收集器清掉:当两个对象相互引用时,他们本身其他的引用已经为0了。
垃圾回收机制还有一个循环垃圾回收器(标记-清除和分代回收),确保释放循环引用对象(a引用b, b引用a, 导致其引用计数永远不为0)。
在垃圾回收的时候,Python 不能进行其它任务,所以如果频繁的进行垃圾回收将大大降低 Python 的工作效率,因此,Python 只会在特定的条件下自动进行垃圾回收,这个条件就是"阈值",在 Python 运行过程中,会记录对象的分配和释放次数,当这两个次数的差值高于阈值的时候,Python 才会进行垃圾回收。
查看阈值:
import gc
gc.get_threshold()
# (700, 10, 10)700 就是垃圾回收启动的阈值,两个 10 是 Python 的垃圾分代回收机制。为了处理如list、dict、tuple等容器对象的循环引用问题,Python 引用了标记-清除和分代回收的策略。
标记清除:
标记清除是一种基于追踪回收 (Tracing GC)技术实现的回收算法,它分为两个阶段:第一阶段是把所有活动对象打上标记,第二阶段是把没有标记的非活动对象进行回收,对象是否活动的判断方法是:从根对象触发,沿着"有向边"遍历所有对象,可达的对象就会被标记为活动对象,不可达的对象就是后面需要清除的对象,如下图
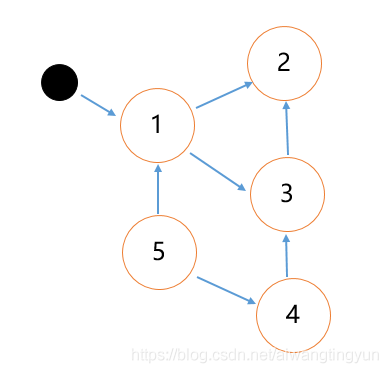
从根对象(小黑点))出发,1、2、3可达,4、5不可达(1-3-4-5 环路),那么1、2、3就会被标记为活动对象,4、5就是会被回收的对象,这种方法的缺点是:每次清除非活动对象前都要扫描整个堆内存里面的对象。
分代回收:
分代回收是一种以空间换时间的操作方式,Python 把所有对象的存货时间分为 3 代(0、1、2),对应着 3 个链表,新创建的对象会被移到第 0 代,当第 0 代的链表总数达到上限时,就会触发 Python 的垃圾回收机制,把所有可以回收的对象回收,而不会回收的对象就会被移到1代,以此类推,第2代的对象是存活最久的对象,当然分代回收是建立在标记清除技术的基础上的。
现在回过头来分析之前的阈值:
>>> gc.get_threshold()
(700, 10, 10)第一个 10 代表每 10 次 0 代的垃圾回收才会触发 1 次 1 代的垃圾回收,每 10 次 1 代的垃圾回收才会触发 1 次 2 代的垃圾回收。当然,也可以手动垃圾回收:
>>> gc.collect()
2内存池机制
分为大内存和小内存。大小以 256 字节为界限,对于大内存使用 Malloc 进行分配,而对于小内存则使用内存池进行分配。
内存池又分为4个层次:Block、Pool、Arean、usedpool,如下图所示
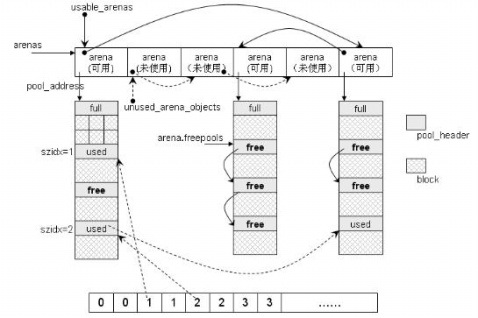
其中 Block 是最小的内存单元,大小为 8 的整数倍。如果想申请 27B 的内存,会分配一个 32B 的 Block,其中申请 size 和 size_index 之间的关系有对应,见下图
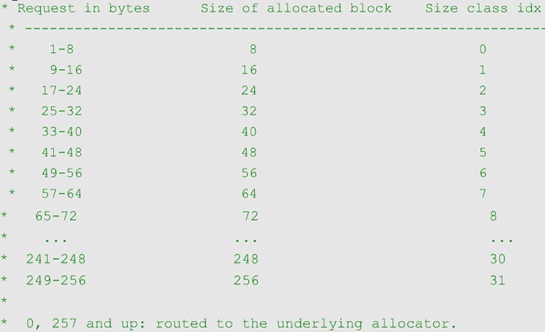
有关 Block 申请机制如下
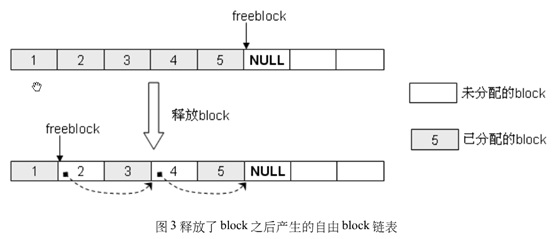
为了避免频繁的申请和释放内存,python的内置数据类型,数值、字符串,查看 Python源码可以看到数值缓存范围为 -5 ~ 257
#ifndef NSMALLPOSINTS
#define NSMALLPOSINTS 257
#endif
#ifndef NSMALLNEGINTS
#define NSMALLNEGINTS 5
#endif对于 -5 ~ 257 范围内的数值,创建之后 Python 会把其加入到缓存池中,当再次使用时,则直接从缓存池中返回,而不需要重新申请内存,如果超出了这个范围的数值,则每次都需要申请内存。下面看个例子:
>>> a = 66
>>> b = 66
>>> id(a) == id(b)
True
>>> x = 300
>>> y = 300
>>> id(x) == id(y)
False字符串的 intern 机制:
Python 解释器中使用了 intern(字符串驻留)的技术来提高字符串效率,所谓 intern 机制,指的是:字符串对象仅仅会保存一份,放在一个共用的字符串储蓄池中,并且是不可更改的,这也决定了字符串时不可变对象。
机制原理:
实现 Intern 机制的方式非常简单,就是通过维护一个字符串储蓄池,这个池子是一个字典结构,如果字符串已经存在于池子中就不再去创建新的字符串,直接返回之前创建好的字符串对象,如果之前还没有加入到该池子中,则先构造一个字符串对象,并把这个对象加入到池子中去,方便下一次获取。
但并非全部的字符串都会采用 intern 机制,只有包括下划线、数字、字母的短字符串才会被 intern,同时字符数不能超过20个,因为如果超过20个字符的话,Python 解释器就会认为这个字符串不常用,不用放入字符串池子中。