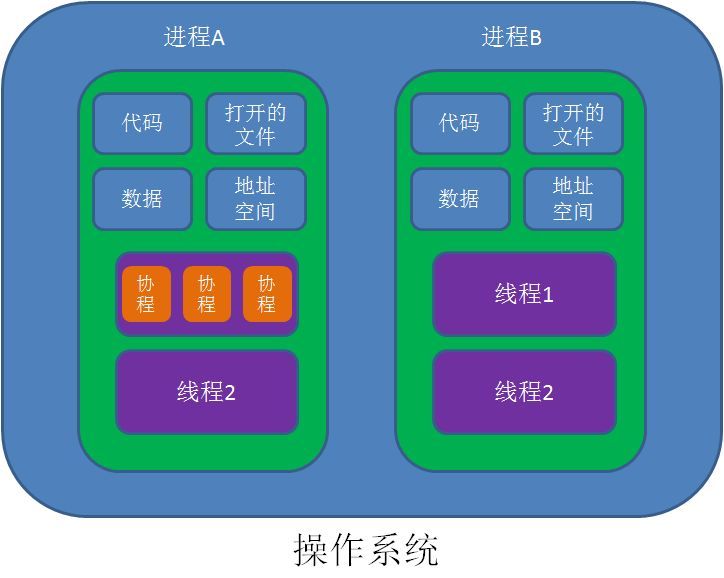
协程
**协程,英文Coroutines,是一种比线程更加轻量级的存在。**正如一个进程可以拥有多个线程一样,一个线程也可以拥有多个协程。
什么是进程和线程
进程是什么呢?
直白地讲,进程就是应用程序的启动实例。比如我们运行一个游戏,打开一个软件,就是开启了一个进程。
进程拥有代码和打开的文件资源、数据资源、独立的内存空间。
线程又是什么呢?
线程从属于进程,是程序的实际执行者。一个进程至少包含一个主线程,也可以有更多的子线程。
线程拥有自己的栈空间。
有人给出了很好的归纳:
对操作系统来说,线程是最小的执行单元,进程是最小的资源管理单元。
无论进程还是线程,都是由操作系统所管理的。
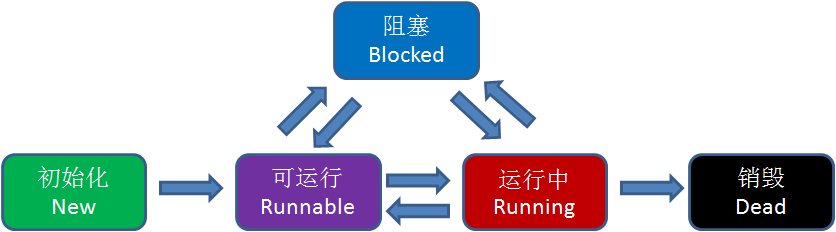
Java中线程具有五种状态:
初始化、可运行、运行中、阻塞、销毁
这五种状态的转化关系如下:
但是,线程不同状态之间的转化是谁来实现的呢?是JVM吗?
并不是。JVM需要通过操作系统内核中的TCB(Thread Control Block)模块来改变线程的状态,这一过程需要耗费一定的CPU资源。
进程和线程的痛点
线程之间是如何进行协作的呢?
最经典的例子就是生产者/消费者模式:
若干个生产者线程向队列中写入数据,若干个消费者线程从队列中消费数据。
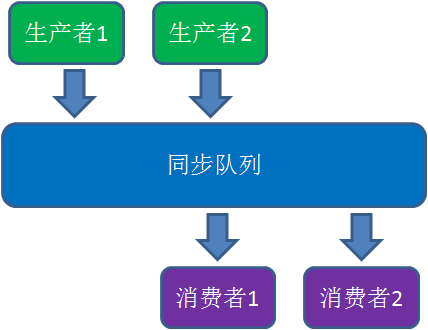
如何用java语言实现生产者/消费者模式呢?
让我们来看一看代码:
public class ProducerConsumerTest {
public static void main(String args[]) {
final Queue<Integer> sharedQueue = new Queue();
Thread producer = new Producer(sharedQueue);
Thread consumer = new Consumer(sharedQueue);
producer.start();
consumer.start();
}
}
class Producer extends Thread {
private static final int MAX_QUEUE_SIZE = 5;
private final Queue sharedQueue;
public Producer(Queue sharedQueue) {
super();
this.sharedQueue = sharedQueue;
}
@Override
public void run() {
for (int i = 0; i < 100; i++) {
synchronized (sharedQueue) {
while (sharedQueue.size() >= MAX_QUEUE_SIZE) {
System.out.println("队列满了,等待消费");
try {
sharedQueue.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
sharedQueue.add(i);
System.out.println("进行生产 : " + i);
sharedQueue.notify();
}
}
}
}
class Consumer extends Thread {
private final Queue sharedQueue;
public Consumer(Queue sharedQueue) {
super();
this.sharedQueue = sharedQueue;
}
@Override
public void run() {
while (true) {
synchronized (sharedQueue) {
while (sharedQueue.size() == 0) {
try {
System.out.println("队列空了,等待生产");
sharedQueue.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
int number = sharedQueue.poll();
System.out.println("进行消费 : " + number);
sharedQueue.notify();
}
}
}
}这段代码做了下面几件事:
定义了一个生产者类,一个消费者类。
生产者类循环100次,向同步队列当中插入数据。
消费者循环监听同步队列,当队列有数据时拉取数据。
如果队列满了(达到5个元素),生产者阻塞。
如果队列空了,消费者阻塞。
上面的代码正确地实现了生产者/消费者模式,但是却并不是一个高性能的实现。为什么性能不高呢?原因如下:
涉及到同步锁。
涉及到线程阻塞状态和可运行状态之间的切换。
涉及到线程上下文的切换。
以上涉及到的任何一点,都是非常耗费性能的操作。
协程的优势
什么是协程
协程不是被操作系统内核所管理,而完全是由程序所控制(也就是在用户态执行)。
这样带来的好处就是性能得到了很大的提升,不会像线程切换那样消耗资源。
协程与进程、线程相比不是一个维度的概念,但是有时候,我们仍然需要将它们做一番比较,具体如下:
协程既不是进程,也不是线程,协程仅仅是一个特殊的函数,协程跟他们就不是一个维度。
一个进程可以包含多个线程,一个线程可以包含多个协程。
一个线程内的多个协程虽然可以切换,但是这多个协程是串行执行的,只能在这一个线程内运行,没法利用CPU多核能力。
4 协程与进程、线程一样,它们的切换都存在上下文切换问题。
表面上,进程、线程、协程都存在上下文切换的问题,但是三者上下文切换又有明显不同,见下表:

协程的使用场景
一个线程内的多个协程是串行执行的,不能利用多核,所以,显然,协程不适合计算密集型的场景。协程适合I/O 阻塞型。
I/O本身就是阻塞型的(相较于CPU的时间世界而言)。就目前而言,无论I/O的速度多快,也比不上CPU的速度,所以一个I/O相关的程序,当其在进行I/O操作时候,CPU实际上是空闲的。
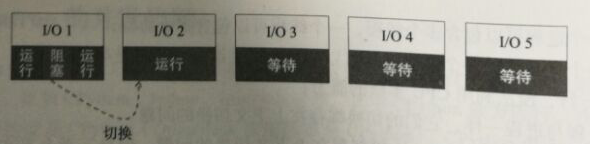
我们假设这样的场景,如下图:1个线程有5个I/O的事情(子程序)要处理。如果我们绝对的串行化,那么当其中一个I/O阻塞时,其他4个I/O并不能得到执行,因为程序是绝对串行的,5个I/O必须一个一个排队等待处理,当一个I/O阻塞时,其它4个也得等着。

而协程能比较好地处理这个问题,当一个协程(特殊子进程)阻塞时,它可以切换到其他没有阻塞的协程上去继续执行,这样就能得到比较高的效率,如下图所示:
上面举的例子是5个I/O处理,如果每秒500个,5万个或500万个呢?已经达到了“I/O密集型”的程度,而**“I/O密集型”确实是协程无法应付的,因为它没有利用多核的能力。这个时候的解决方案就是“多进程+协程”了。**
所以说,I/O阻塞时,利用协程来处理确实有优点(切换效率比较高),但是我们也需要看到其不能利用多核的这个缺点,必要的时候,还需要使用综合方案:多进程+协程。
Kotlin Jetpack 实战:图解协程原理
个人理解
Kotlin 的协程,核心在于其内部新定义实现的单例 子类 ContinuationImpl,本质为 CPS + 状态机,核心使得本质运行。
ContinuationImpl 实现了对状态机的状态的标识,invokeSuspend() 回调函数对 CPS(this) 的回调。
大致步骤如下:
对各挂起函数 (
suspend修饰 ) 进行CPS转换(Continuation-Passing-Style Transformation)为 continuation 参数赋值,如果该值为
ContinuationImpl类型,则延用该类,否则调用定义的子类ContinuationImpl进行包装 ( 一般只要在初次赋值包装 )。进入
whe(continuation.label){ x -> {}}状态机判断,更新状态标记label并调用IO线程执行挂起函数体,其中挂起函数withContext(Dispatchers.IO){ x }的调用将直接返回 挂起状态码,状态机状态机检测到该值后,将响应挂起函数的回调。若加入
suspend修饰的函数中不包含withContext(Dispatchers.IO){ x }实现挂起进程,则该函数为伪函数,状态机将判断其未进入挂起状态,通过跳转到when前的label赋值进入下一状态,也即该函数还是在主线程完成的。循环往复,直至到达最终状态为止。