SELF-INSTRUCT: Aligning Language Models with Self-Generated Instructions
SELF-INSTRUCT: Aligning Language Models with Self-Generated Instructions
Wang, Yizhong, Yeganeh Kordi, Swaroop Mishra, Alisa Liu, Noah A. Smith, Daniel Khashabi, and Hannaneh Hajishirzi. Self-Instruct: Aligning Language Models with Self-Generated Instructions: arXiv:2212.10560[Z]. arXiv,2023. (2023–05–25).
主要贡献
- 提出了一种框架:SELF-INSTRUCT,该框架可以仅使用最少的人工标注,生成大量的用于指令调优的数据;
- 通过多个实验验证了文章方法的有效性;
- 文章发布了52K的使用SELF-INSTRUCT指令数据集,以及一份人工手动编写的新任务数据集用来构建和评估指令调优模型。
主要流程
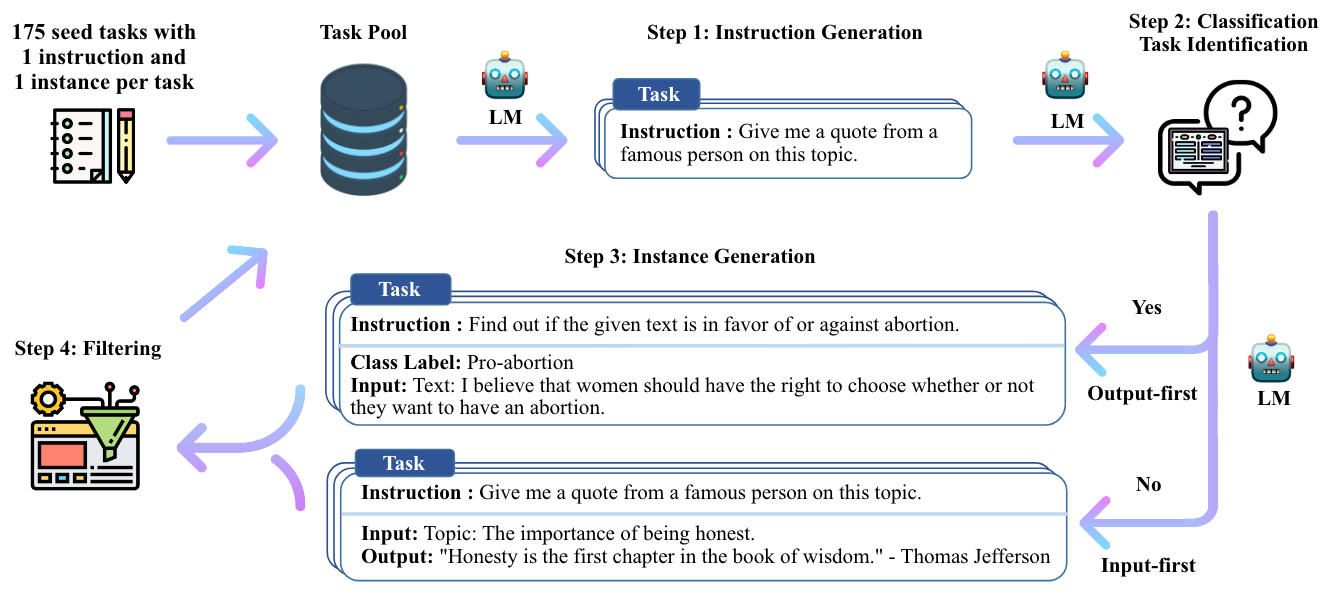
指令定义
原文定义如下:
The instruction data we want to generate contains a set of instructions {𝐼𝑡}, each of which defines a task 𝑡 in natural language. Task 𝑡 has 𝑛𝑡 ≥ 1 input-output instances {(𝑋𝑡,𝑖, 𝑌𝑡,𝑖)}𝑛𝑡 𝑖=1. A model 𝑀 is expected to produce the output, given the task instruction and the corresponding input: 𝑀(𝐼𝑡, 𝑋𝑡,𝑖) = 𝑌𝑡,𝑖, for 𝑖 ∈ {1, ... , 𝑛𝑡}.一条指令数据集由instruction、input、output三个部分组成。需要注意的是insturction和input之间没有严格的区分,比如下面两个例子表达的意思是一样的,只是在形式上不一样。
# 例子1
instruction: "write an essay about school safety"
input:""
output:"...."
# 例子2
instruction: "write an essay about the following topic"
input:"school safety"
output:"...."步骤一:指令生成
prompt
步骤二 分类任务识别
步骤三 实例生成
给定指令及其任务类别,为每个指令生成实例。根据指令是否是分类任务,采取不同的prompt模板。
步骤四 过滤和后处理
为了保证指令的多样性,一个指令只有与任务池中已有的指令的ROUGE-L小于0.7才会被考虑加入到任务池,同时过滤掉包含一些特殊词(如image/picture/graph等)的生成指令,因为这些指令LM还不会处理。(注:虽然过滤是在论文中的第四个步骤,但是代码实现时,对于指令的过滤是在第一步生成指令的时候就过滤了不满足要求的指令,当任务池中的指令达到生成数量比如52k后就停止第一步的指令生成)
对于生成的实例,过滤掉重复的、过滤掉与相同input不同output的实例。
并用启发式方法识别和过滤掉一些实例,比如是否太长、是否太短、输出是输入的重复等。
这步骤的代码可以看一下学习学习。
实验
限制
- 长尾效应还比较严重:self-instruct依赖于LMs生成数据,会继承LM的缺陷,偏向于出现频率高的词。在常见的指令上效果可能不错,在长尾样本上可能效果比较差。
- 依赖大模型:依赖大模型的归纳偏差(inductive biases),可能只在大模型上效果比较好,由于大模型资源要求比较大,这也限制了小模型的使用。
- 可能会增强LM的偏见:可能会放大social bias,例如模型可能无法产生比较balanced的label。
参考
Repo: https://github.com/yizhongw/self-instruct
Arxiv: http://arxiv.org/abs/2212.10560
低成本指令数据集构建:《Self-Instruct: Aligning Language Model with Self Generated Instructions》阅读笔记-CSDN博客
ACL2023 | 大模型如何快速构建指令遵循数据集?Self-Instruct:只需175条种子数据追上InstructGPT...-CSDN博客