iStep 改造
iStep 改造
OJ+在线课程+课程/算法双向推荐+伙伴匹配
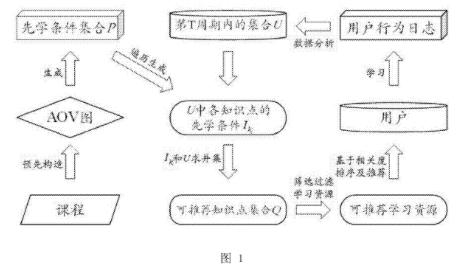
image-20250703202801181 该算法的核心思想是利用课程知识点之间的先后顺序关系(拓扑结构),为学习者提供精准、个性化的学习资源推荐,同时有效解决推荐系统中的冷启动和数据稀疏性问题。
第一步:构建课程知识图谱(AOV图)与先学条件
- 预先构造AOV图: 算法首先需要为每门课程定义其内部所有知识点之间的“制约关系”或“先决关系” 。例如,学习“指针”之前必须先学习“变量”。这种关系可以用一种名为“顶点活动网”(Activity On Vertex, AOV)的图来表示 。在这个图中,每个节点(顶点)代表一个知识点,有向边则代表知识点之间的学习顺序(依赖关系) 。专利图 2 就展示了一个包含 14 个知识点的课程 AOV 图示例 。
- 生成先学条件集合: 基于构建好的AOV图,系统通过拓扑排序算法,为每一个知识点确定其所有前置必须学习的知识点 。这个前置知识点的集合被称为该知识点的“先学条件” 。例如,在图2的示例中,知识点 k3 的先学条件是 k1 和 k2 。所有知识点的先学条件集合会被预先计算并存储起来,形成一个总的“先学条件集合P” 。
第二步:分析用户学习进度
- 获取用户学习数据: 系统会追踪和分析用户的学习行为日志 。
- 确定已完成知识点: 通过数据分析,系统可以确定用户在当前学习周期(例如本周)内已经学会了哪些知识点,这个集合被记为“集合U” 。例如,在一个具体实施案例中,假设用户本周学完了 k10 和 k11 两个知识点,那么 U={k10,k11}。
第三步:确定可推荐的知识点范围
- 匹配先学条件: 系统会遍历用户已完成的知识点集合U,并从预先生成的总集合P中,找出U中每个知识点对应的“先学条件” 。
- 生成可推荐知识点集合Q: 将用户当前已学会的知识点集合U,与这些知识点的所有“先学条件”进行合并(求并集),就得到了一个更大的集合Q 。这个集合Q代表了到目前为止,该用户已经完成学习的所有知识点 。因此,集合Q构成了系统可以向该用户推荐的所有知识点的基础范围。任何将要被推荐的学习资源,其所包含的知识点必须完全在这个Q集合之内 。
第四步:筛选并排序推荐资源
- 匹配与过滤: 系统中的每一个学习资源(如一个视频、一篇文章、一道练习题)都会被标记上其所关联的一个或多个知识点(集合S)。系统会用每个资源的知识点集合S与用户的可推荐知识点集合Q进行比较。只有当一个资源的所有知识点都包含在集合Q中时(即 S⊆Q),这个资源才会被初步筛选出来,成为候选推荐资源 。
- 相关度排序(加权拓扑距离): 为了在众多候选资源中找出最相关的进行推荐,算法引入了“加权拓扑距离”的概念进行排序 。
- 拓扑距离: 在AOV图中,任意两个知识点之间的最短路径长度被定义为它们的“拓扑距离” 。
- 加权拓扑距离: 一个学习资源(其知识点集合为X)与用户当前学习进度(其知识点集合为Y,在这里就是集合U)的加权拓扑距离,是计算资源X中的每一个知识点到集合Y的“最短拓扑距离”之和 。简单来说,这个值越小,代表该学习资源中的知识点与用户最近学习的知识点在课程结构上“距离”越近,相关性越高。
- 最终推荐: 系统会计算所有候选资源与用户当前学习进度(集合U)的加权拓扑距离,并按距离从小到大的顺序进行排序。排名靠前的资源将被优先推荐给用户 。例如,在专利的案例中,资源2(包含 k10)的加权拓扑距离为0,而资源1(包含 k1,k5)的距离为5,因此资源2会被优先推荐 。
算法优势
- 解决冷启动问题: 由于推荐是基于预先构建的课程知识结构(AOV图),即使系统没有任何用户行为数据,也能根据知识点的前后关系进行基础推荐 。
- 个性化与准确性: 推荐内容严格基于每个用户已掌握的知识(集合Q),并根据其最近的学习内容(集合U)进行相关度排序,保证了推荐的个性化和准确性 。
- 高效性: 关键的AOV图和先学条件集合都是预先计算好的,在进行推荐时,系统只需进行集合的匹配和快速的距离计算,避免了在海量数据中进行复杂运算,从而解决了数据稀疏性问题并提高了推荐效率 。
Java 实现思路
核心思路
我们将创建一个推荐服务类,该类首先会根据课程的知识点依赖关系进行 预处理,计算出所有知识点的先学条件和它们之间的拓扑距离。在接收到推荐请求时,它会根据用户的学习历史,快速地执行 过滤 和 排序 两个核心操作,最后返回一个有序的推荐资源列表。
第一步:定义核心数据结构 (Java Beans)
首先,我们需要定义用于表示知识点、学习资源和图结构的核心类。
KnowledgePoint.java(知识点): 一个简单的类来表示图中的节点。// 简单起见,我们直接使用String类型作为知识点的唯一标识符,如"k1", "k2"。 // 在复杂系统中,可以创建一个包含ID、名称、描述等属性的类。 // public class KnowledgePoint { // private String id; // private String name; // // ... getters and setters // }LearningResource.java(学习资源): 表示一个具体的学习材料,如视频或文章。它必须包含其关联的知识点集合 S。import java.util.Set; public class LearningResource { private String id; private String title; // 资源关联的知识点集合S private Set<String> knowledgePointIds; public LearningResource(String id, String title, Set<String> knowledgePointIds) { this.id = id; this.title = title; this.knowledgePointIds = knowledgePointIds; } // Getters public String getId() { return id; } public String getTitle() { return title; } public Set<String> getKnowledgePointIds() { return knowledgePointIds; } @Override public String toString() { return "LearningResource{" + "id='" + id + '\'' + ", title='" + title + '\'' + ", knowledgePoints=" + knowledgePointIds + '}'; } }
第二步:构建AOV图并预处理计算
这是算法的核心准备阶段。我们需要一个服务类来封装图的构建、先学条件集合P的生成以及拓扑距离的计算。这些操作在服务启动时执行一次即可。
import java.util.*; import java.util.stream.Collectors; public class RecommendationService { // 1. AOV图的数据结构: 使用邻接表表示 // Key: 知识点ID, Value: 该知识点直接指向的后继知识点ID列表 private final Map<String, List<String>> aovGraph = new HashMap<>(); // 反向图,用于快速查找先学节点 private final Map<String, List<String>> reversedAovGraph = new HashMap<>(); // 2. 预处理结果存储 // 知识点集合V的先学条件集合P (I_k) [cite: 33, 75] private final Map<String, Set<String>> prerequisiteSets = new HashMap<>(); // 任意两个知识点之间的拓扑距离D(ki, kj) private final Map<String, Map<String, Integer>> topologicalDistances = new HashMap<>(); // 系统中所有的学习资源 private final List<LearningResource> allResources = new ArrayList<>(); /** * 构造函数,用于初始化和预处理 */ public RecommendationService(Map<String, List<String>> graphData, List<LearningResource> resources) { this.allResources.addAll(resources); // 初始化AOV图和反向图 for (String node : graphData.keySet()) { aovGraph.putIfAbsent(node, new ArrayList<>()); reversedAovGraph.putIfAbsent(node, new ArrayList<>()); } graphData.forEach((from, toList) -> { aovGraph.get(from).addAll(toList); toList.forEach(to -> { reversedAovGraph.putIfAbsent(to, new ArrayList<>()); reversedAovGraph.get(to).add(from); }); }); // 执行预处理计算 preprocess(); } /** * 预处理方法:计算先学条件集P和拓扑距离 */ private void preprocess() { Set<String> allNodes = aovGraph.keySet(); // 1. 计算每个知识点的先学条件集合 P = {I_k1, I_k2, ...} // 我们通过遍历反向图来找到所有祖先节点 for (String node : allNodes) { Set<String> prerequisites = new HashSet<>(); findAllPrerequisites(node, prerequisites); prerequisiteSets.put(node, prerequisites); } // 2. 计算所有节点对之间的最短路径(拓扑距离) // 使用从每个节点开始的广度优先搜索 (BFS) for (String startNode : allNodes) { topologicalDistances.put(startNode, calculateDistancesFrom(startNode)); } } // 辅助方法: 递归查找所有先学条件(所有祖先节点) private void findAllPrerequisites(String node, Set<String> visited) { List<String> parents = reversedAovGraph.getOrDefault(node, Collections.emptyList()); for (String parent : parents) { if (visited.add(parent)) { // 如果添加成功(说明之前未访问过) findAllPrerequisites(parent, visited); } } } // 辅助方法: 从一个源节点计算到所有其他节点的拓扑距离 // 1. 使用广度优先搜索,一圈一圈向远搜索 private Map<String, Integer> calculateDistancesFrom(String startNode) { Map<String, Integer> distances = new HashMap<>(); // 用于存储距离,并兼做“已访问”标记 Queue<String> queue = new LinkedList<>(); // BFS的核心数据结构:队列 // 初始化 distances.put(startNode, 0); // 起点到自身的距离为0 queue.add(startNode); // 将起点放入队列 while (!queue.isEmpty()) { String current = queue.poll(); // 取出当前层的节点 int currentDist = distances.get(current); // 遍历当前节点的所有邻居 for (String neighbor : aovGraph.getOrDefault(current, Collections.emptyList())) { // 2. 若该点已经计算过,则跳过,这是有 BFS 提供的最短路径距离保障 if (!distances.containsKey(neighbor)) { // 如果邻居节点从未被访问过(即距离未被设置) distances.put(neighbor, currentDist + 1); // 设置其距离 queue.add(neighbor); // 将其加入队列,待下一层处理 } } } return distances; } // ... 推荐方法将在下一步实现 }第三步:实现核心推荐逻辑
现在,在
RecommendationService.java中添加主推荐方法。此方法将执行专利中描述的步骤2到步骤5。// 在 RecommendationService.java 类中继续添加 /** * 核心推荐方法 * @param userLearnedSetU 用户在当前周期学习完成的知识点集合U [cite: 34] * @param topN 需要推荐的资源数量 * @return 按相关度排序的学习资源列表 */ public List<LearningResource> recommend(Set<String> userLearnedSetU, int topN) { // 步骤 3 & 4: 确定可推荐知识点集合 Q // Q = U ∪ (U中所有知识点的先学条件) [cite: 36, 60] Set<String> recommendablePoolQ = new HashSet<>(userLearnedSetU); for (String learnedPoint : userLearnedSetU) { recommendablePoolQ.addAll(prerequisiteSets.getOrDefault(learnedPoint, Collections.emptySet())); } // 步骤 5.1: 筛选学习资源 // 筛选出满足条件 S ⊆ Q 的学习资源 [cite: 37, 64] List<LearningResource> candidateResources = allResources.stream() .filter(resource -> recommendablePoolQ.containsAll(resource.getKnowledgePointIds())) .collect(Collectors.toList()); // 步骤 5.2: 根据加权拓扑距离进行相关度排序 // 计算每个候选资源与集合U的加权拓扑距离并排序 [cite: 37] candidateResources.sort((res1, res2) -> { double score1 = calculateWeightedTopologicalDistance(res1.getKnowledgePointIds(), userLearnedSetU); double score2 = calculateWeightedTopologicalDistance(res2.getKnowledgePointIds(), userLearnedSetU); return Double.compare(score1, score2); // 升序排列,距离越小越好 }); // 取前N个学习资源执行推荐 return candidateResources.stream().limit(topN).collect(Collectors.toList()); } /** * 辅助方法:计算加权拓扑距离 * @param resourceKnowledgePoints 学习资源的知识点集合 X * @param userLearnedSet 用户当前学习的知识点集合 Y (即 U) * @return 加权拓扑距离总和 */ private double calculateWeightedTopologicalDistance(Set<String> resourceKnowledgePoints, Set<String> userLearnedSet) { // 专利定义:Σ Min(D(ki, kj)) for ki in X, kj in Y [cite: 39, 65] double totalDistance = 0; for (String ki : resourceKnowledgePoints) { int minDistance = Integer.MAX_VALUE; for (String kj : userLearnedSet) { // 注意:距离是单向的。我们需要的是从用户已学(kj)到资源(ki)的距离。 // 如果kj能到达ki,则有距离;否则距离为无穷大。 Integer distance = topologicalDistances.getOrDefault(kj, Collections.emptyMap()).get(ki); if (distance != null && distance < minDistance) { minDistance = distance; } } // 如果资源中的某个知识点是用户已学的,距离为0 if (userLearnedSet.contains(ki)) { minDistance = 0; } totalDistance += (minDistance == Integer.MAX_VALUE) ? 1000 : minDistance; // 使用一个较大的值代表不可达 } return totalDistance; }第四步:整合与使用
现在,我们可以创建一个
Main类来模拟整个流程,从构建图到获取推荐结果。import java.util.Arrays; import java.util.HashMap; import java.util.HashSet; import java.util.List; import java.util.Map; import java.util.Set; public class Main { public static void main(String[] args) { // 1. 定义课程的AOV图结构 (基于图2) [cite: 91] Map<String, List<String>> graphData = new HashMap<>(); graphData.put("k1", Arrays.asList("k3", "k4")); graphData.put("k2", Arrays.asList("k3", "k5")); graphData.put("k3", Arrays.asList("k8")); graphData.put("k4", Arrays.asList("k5", "k6", "k7")); graphData.put("k5", Arrays.asList("k7")); graphData.put("k6", Arrays.asList("k10")); graphData.put("k7", Arrays.asList("k11", "k12")); graphData.put("k8", Arrays.asList("k9", "k13")); graphData.put("k9", Arrays.asList("k14")); // 叶子节点 graphData.put("k10", Arrays.asList()); graphData.put("k11", Arrays.asList()); graphData.put("k12", Arrays.asList()); graphData.put("k13", Arrays.asList()); graphData.put("k14", Arrays.asList()); // 2. 定义系统中的学习资源 [cite: 89] List<LearningResource> allResources = Arrays.asList( new LearningResource("res1", "资源1", new HashSet<>(Arrays.asList("k1", "k5"))), new LearningResource("res2", "资源2", new HashSet<>(Collections.singletonList("k10"))), new LearningResource("res3", "资源3", new HashSet<>(Arrays.asList("k5", "k8"))), new LearningResource("res4", "资源4", new HashSet<>(Arrays.asList("k12"))), new LearningResource("res5", "资源5", new HashSet<>(Arrays.asList("k3"))) ); // 3. 初始化推荐服务 (执行预处理) RecommendationService service = new RecommendationService(graphData, allResources); // 4. 模拟用户请求 // 假设用户当前学习周期完成了 k10 和 k11 [cite: 83] Set<String> userLearnedSetU = new HashSet<>(Arrays.asList("k10", "k11")); System.out.println("用户当前学习的知识点 U: " + userLearnedSetU); // 5. 获取推荐结果 List<LearningResource> recommendations = service.recommend(userLearnedSetU, 3); System.out.println("\n为该用户推荐的学习资源 (按相关度排序):"); recommendations.forEach(System.out::println); // --- 另一个例子 --- System.out.println("\n--- 另一个例子 ---"); Set<String> userLearnedSetU2 = new HashSet<>(Arrays.asList("k3")); System.out.println("用户当前学习的知识点 U: " + userLearnedSetU2); List<LearningResource> recommendations2 = service.recommend(userLearnedSetU2, 3); System.out.println("\n为该用户推荐的学习资源 (按相关度排序):"); recommendations2.forEach(System.out::println); } }实现说明
- 预处理的重要性:
preprocess()方法是性能的关键。它将耗时的图遍历(计算先学条件和所有节点对的距离)提前完成。这样,在处理实际推荐请求时,算法只需要进行高效的集合操作和查表,从而实现快速响应。 - 图的表示: 我们使用了
Map<String, List<String>>(邻接表) 来表示AOV图,这是在Java中表示稀疏图(大部分节点之间没有连接)的标准且高效的方式。同时建立一个反向图可以极大地加速查找先学条件的过程。 - 距离计算:
calculateDistancesFrom方法使用了广度优先搜索(BFS)来计算单源最短路径,这是在无权图中计算最短路径的标准算法,其结果就是专利中定义的拓扑距离 2。 - 推荐逻辑:
recommend方法严格遵循了专利描述的流程:首先确定总知识库Q,然后用Q过滤资源,最后用加权拓扑距离对候选资源进行排序。 - 代码的健壮性: 在实际生产环境中,需要对各种边界情况进行处理,例如图中存在环(AOV图理论上是无环有向图)、知识点ID不存在等。可以添加更多的错误处理和日志记录。
解释
RecommendationService中各个属性(成员变量)的作用,以及如何通过具体的例子来初始化它们这些属性的设计完全是为了服务于专利中描述的算法,它们可以分为两类:
- 输入数据 (Inputs): 描述课程和资源的基础信息。
- 预处理缓存 (Pre-computation Cache): 为了实现“快速”推荐,提前计算并存储好的中间结果。
1. 属性设置的原因 (The "Why")
让我们逐一分析
RecommendationService中的每个属性:属性名 作用 对应专利中的概念 allResources[输入] 存储系统中所有可供推荐的学习资源。推荐系统需要知道它到底有哪些“东西”可以推荐。 "每个学习资源都对应着相关联的一个知识点集合S" 111 aovGraph[输入] 存储课程知识点的依赖关系图。这是整个算法的基石,定义了知识点的学习顺序。 "预先构造V对应的AOV图" 222222222 reversedAovGraph[预处理缓存] aovGraph的反向图。专门为了能极速查找到任何一个知识点的“父节点”(直接前驱)。这在计算“先学条件”时非常高效。(这是一个实现细节,用于高效完成专利步骤1) prerequisiteSets[预处理缓存] 存储每个知识点的所有先学条件。当用户学完一个知识点,我们可以瞬间拿出它需要的所有前置知识,而无需再次遍历图。 "生成V的先学条件集合 P" 333333333 topologicalDistances[预处理缓存] 存储任意两个知识点之间的最短路径长度。用于最终排序,避免在每次推荐时都去计算距离,从而实现快速排序。 "拓扑距离D(ki,kj)为AOV图中任意两个知识点...之间的最短路径长度" 4444 核心思想:
reversedAovGraph,prerequisiteSets,topologicalDistances这三个“缓存”属性,将耗时的图遍历计算全部提前完成。这样,当用户请求推荐时,服务只需进行简单的查表和集合运算,响应速度极快,完美契合了专利名称中“快速推荐”的要求。2. 属性设置的方法与具体示例 (The "How")
我们以专利附图中的图2为例,来具体说明如何设置这些属性。
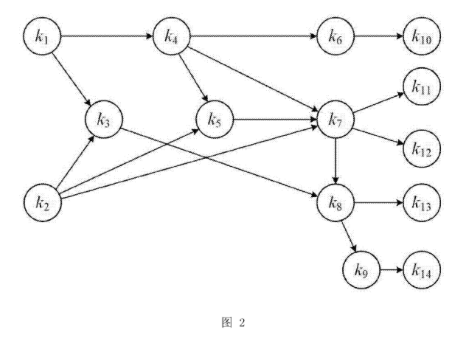
image-20250703202723653 步骤A: 设置输入数据 (
allResources和aovGraph)这是在创建
RecommendationService实例时,需要我们手动提供的数据。设置 allResources:
您需要将系统里所有的学习资源整理出来。根据专利中的例子 6,我们可以这样创建:
// 假设系统中有这5个学习资源 List<LearningResource> allResources = Arrays.asList( // 资源1关联知识点 {k1, k5} new LearningResource("res1", "资源1:变量与指针基础", new HashSet<>(Arrays.asList("k1", "k5"))), // 资源2关联知识点 {k10} new LearningResource("res2", "资源2:高级指针应用", new HashSet<>(Collections.singletonList("k10"))), // 资源3关联知识点 {k5, k8} new LearningResource("res3", "资源3:指针与结构体", new HashSet<>(Arrays.asList("k5", "k8"))), // 其他资源... new LearningResource("res4", "资源4:链表操作", new HashSet<>(Arrays.asList("k12"))), new LearningResource("res5", "资源5:数据结构入门", new HashSet<>(Arrays.asList("k3"))) );设置 aovGraph:
您需要根据课程设计,将图2的结构“翻译”成代码。邻接表的
Map<String, List<String>>结构非常适合做这件事。// "翻译"图2的结构 Map<String, List<String>> graphData = new HashMap<>(); graphData.put("k1", Arrays.asList("k3", "k4")); // k1 指向 k3 和 k4 graphData.put("k2", Arrays.asList("k3", "k5")); // k2 指向 k3 和 k5 graphData.put("k3", Arrays.asList("k8")); // k3 指向 k8 graphData.put("k4", Arrays.asList("k5", "k6", "k7"));// k4 指向 k5, k6, k7 graphData.put("k5", Arrays.asList("k7")); graphData.put("k6", Arrays.asList("k10")); graphData.put("k7", Arrays.asList("k11", "k12")); graphData.put("k8", Arrays.asList("k9", "k13")); graphData.put("k9", Arrays.asList("k14")); // 叶子节点,没有出度,对应一个空列表 graphData.put("k10", new ArrayList<>()); graphData.put("k11", new ArrayList<>()); graphData.put("k12", new ArrayList<>()); graphData.put("k13", new ArrayList<>()); graphData.put("k14", new ArrayList<>());现在,您就可以用这两个准备好的数据来创建服务实例了:
RecommendationService service = new RecommendationService(graphData, allResources);
步骤B: 预处理属性的自动生成
当
new RecommendationService(...)被调用时,其构造函数会自动调用preprocess()方法,填充剩下的三个“缓存”属性。我们来看看它们内部的样子:reversedAovGraph 的生成:
代码会自动遍历 aovGraph 来创建反向图。例如,因为 k1 指向 k3,那么在反向图中,k3 的父节点列表里就有 k1。
- 结果示例:
reversedAovGraph中会有这样的条目:{"k3": ["k1", "k2"], "k7": ["k4", "k5"], ...}
- 结果示例:
prerequisiteSets (先学条件集合 P) 的生成:
代码会利用反向图,为每个节点递归地寻找所有祖先。
- 以
k10为例:- 找
k10的父节点 ->k6。集合为{k6}。 - 找
k6的父节点 ->k4。集合为{k6, k4}。 - 找
k4的父节点 ->k1。集合为{k6, k4, k1}。 k1没有父节点,结束。
- 找
- 最终结果:
prerequisiteSets中会生成一个条目:{"k10": {"k1", "k4", "k6"}}。这与专利中的描述完全一致。 - 同理,对于
k11,其先学条件集合为{"k1", "k2", "k4", "k5", "k7"}。
- 以
topologicalDistances 的生成:
代码会对图中的每个节点作为起点,运行一次广度优先搜索(BFS)来计算它到其他所有可达节点的最短距离。
结果示例:
topologicalDistances是一个嵌套的Map,它看起来像这样:{ "k1": {"k3": 1, "k4": 1, "k8": 2, "k6": 2, "k7": 2, ...}, "k2": {"k3": 1, "k5": 1, "k8": 2, "k7": 2, ...}, ... }例如,从
k1到k7的最短路径是k1 -> k4 -> k7,长度为2,所以topologicalDistances.get("k1").get("k7")的值就是2。这个值在最终排序时会被直接查询,无需重新计算。
总结来说,只需要提供基础的课程结构(
aovGraph)和资源列表(allResources),RecommendationService就会自动完成所有复杂的预处理工作,为快速、精准的个性化推荐做好准备。协同过滤算法
该算法的冷启动问题,基于已有课程手动构建 AOV 网络(Activity On Vertex Network,一种用有向图表示任务或活动之间优先关系的模型)来解决,让用户注册时选择感兴趣的知识点,如果不选则默认推荐,有一张默认推荐数据的表,由系统配置。
引出下一个问题,手动构建->在探索使用 ai 自动话构建,比如:
- 使用ai分别对课程和算法题进行打标,通过知识点标签打通课程和算法题
- 基于知识点标签匹配课程及算法题
- 基于课程 AOV 和用户学习行为记录(课程、算法题)进行个性化推荐
课程推荐、学习指导
基于用户算法题提交情况、课程练习情况等,分析薄弱点来推荐课程,总之基于tag,存在理论上的可行性,假装实现了
任务:根据用户的算法题提交统计情况及相关课程信息,为用户提供课程学习指导。 以下是用户算法题提交统计: [ {question_id: xx question_name: xx question_content: xx question_tag: xx 提交统计: 提交x次,错误类型1x次,错误类型2x次...通过x次}, ... ] 相关课程信息: [ {course_name: xx course_description: xx course_tag: xx }, ] 要求: 1. 给出学习指导建议 2. 给出推荐学习的课程 输出格式: { "learn_advice": xx, "recommend_course": xx }课程题库
drop table course_question if exist; create table course_question { id bigint not null primary key, type int not null comment "1 - 单选, 2 - 多选,3 - 判断,4 - 填空,5 - 简答,6 - 算法", title varchar(512) comment "算法类型,直接存 算法题id", content varchar(1024), answer varchar(1024), }; create table course_test { xx };
页面设计:
- tab包括 首页、课程、题库、练习,含有我的头像进入个人中心,侧边栏
- 首页是课程推荐,侧边栏是推荐课程、推荐题库、推荐练习
标签匹配算法,gemini说:
✅ 编辑距离算法
✅ 余弦相似度
❌ TF-IDF(也使用到了余弦相似度)
即词频-逆文档频率,是一种用于评估一个词语对于一个文件集(或语料库)中的一份文件的重要程度的统计方法。
它的核心思想是:一个词在一个文档中出现的频率越高,且在所有文档中出现的频率越低,就代表这个词对该文档的区分度越高,越能代表该文档的主题。


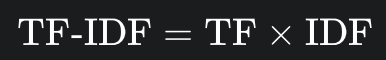
杰卡德相似系数 (Jaccard Similarity): 即交集/并集
加权匹配/自定义评分
将权重融入余弦相似度计算,比如在学习某方面的内容时,部分标签有较高的权重,因此我们可以为某课程或某类型队伍维护单独的标签权重表用于计算
最终方案:
余弦相似度+加权
即将原先每个tag对应的0/1,替换为0/对应权重
流程:
用户和队伍使用同一套tag系统,涉及到课程或练习或算法题的推荐则使用基于知识点的拓扑距离推荐
若用户选定某课程进行组队,或在创建组队时选择了某种类型,则使用加权匹配用户/队伍
若用户未具体指定,则默认使用用户间基于tag的余弦相似度匹配用户/队伍
若用户未具体指定,用户也没设置tag,则降级为随机匹配
扩展点
深化标签系统
标签权重 (Tag Weighting): 让用户自己标记哪些标签对他们更重要。例如,在找开发队友时,用户可以把 "Python" 标记为“必须”,把 "UI设计" 标记为“加分项”。
标签关系 (Tag Ontology): 建立标签之间的关系图谱。系统需要知道 "机器学习" 和 "深度学习" 是高度相关的,"后端开发" 和 "数据库" 也是。这样,即使用户标签不完全一致,但只要在语义上相近,也能获得不错的匹配度。这可以通过Word2Vec等NLP技术实现。
引入新的用户维度
显式数据
水平/熟练度 (Proficiency): 让用户为他们的技能标签选择等级(如:
Python: 精通,Photoshop: 了解)。目标/动机 (Goals): 用户组队的目的是什么?(如:“上分冲段位”、“休闲娱乐”、“完成项目”、“学习交流”)。目标一致是组队成功的关键。(用户填写,使用llm判断)
可用时间 (Availability): 用户的时区、通常在线的时间段(如“工作日晚上”、“周末全天”)。这是最实际的匹配依据之一。
角色/定位 (Roles): 在团队中期望扮演的角色。游戏里是“坦克/治疗/输出”,项目中是“前端/后端/产品/设计”。这可以实现互补性匹配,而不仅仅是相似性匹配。(PS:较简单的方法或许可以再维护一个互补权重专门用于互补匹配)
隐式/行为数据 (Implicit/Behavioral Data):
- 活跃度 (Activity Level): 用户登录频率、响应组队邀请的速度等。可以将更活跃的用户优先推荐。
- 信誉/评价系统 (Reputation System): 队伍解散后,成员之间可以相互评价(如:“沟通友好”、“技术大神”、“鸽子王”)。这个数据是预测未来组队质量的黄金指标。
- 历史行为 (Historical Behavior): 用户过去成功加入了什么样的队伍?和哪些人组队时间最长?系统可以从中学习用户的隐含偏好。
升级匹配逻辑
从相似匹配到互补匹配 (Complementary Matching): 当引入“角色”维度后,系统的目标就变成了“组建一个结构完整的队伍”。比如,一个寻找项目的“后端开发者”应该优先匹配“前端开发者”和“UI设计师”,而不是其他“后端开发者”。
引入机器学习 (Machine Learning): 当积累了足够多的数据(哪些队伍成功了,哪些失败了)之后,可以训练一个预测模型。模型的输入是两个(或多个)用户的完整画像(标签、行为、信誉等),输出是一个“兼容性分数”。这种方式可以发现人难以察觉的复杂匹配模式,是最终极的优化方向。