Lock
Lock
死锁面试题(什么是死锁,产生死锁的原因及必要条件)_AddoilDan的博客-CSDN博客_死锁
1、什么悲观锁?
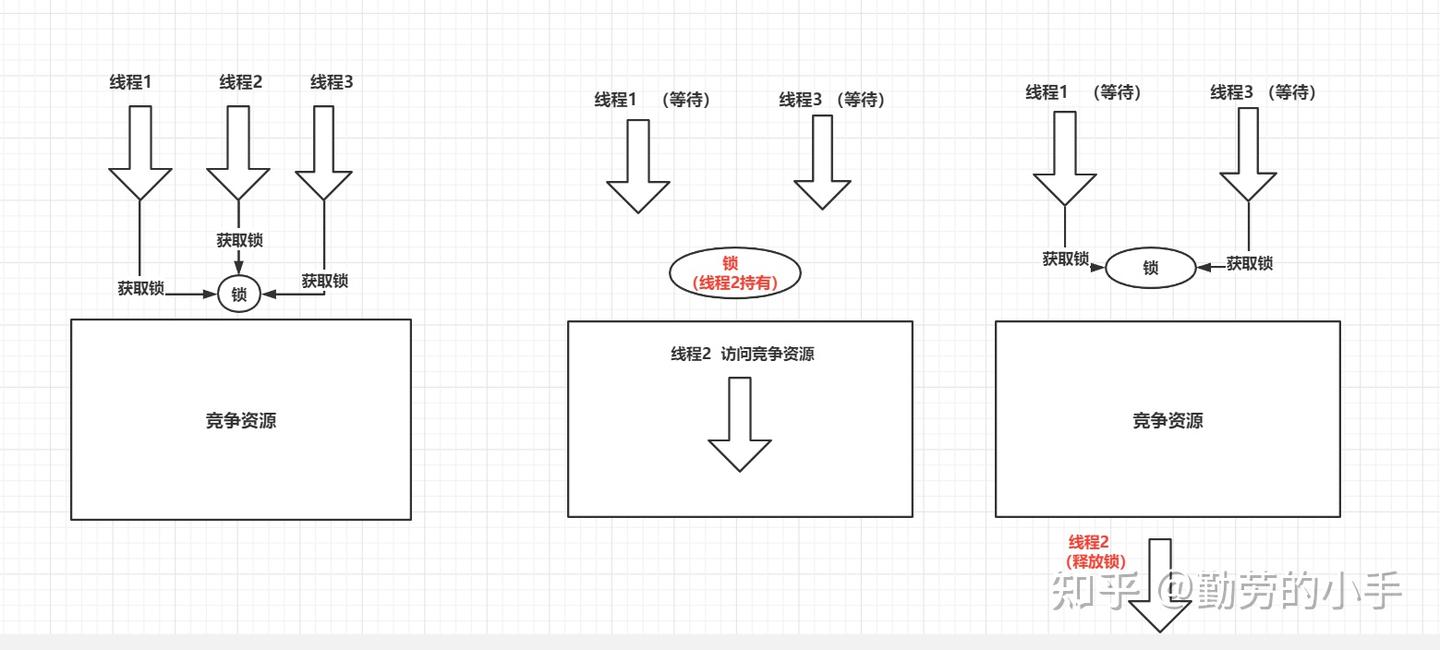
顾名思义,悲观锁是基于一种悲观的态度类来防止一切数据冲突,它是以一种预防的姿态在修改数据之前把数据锁住,然后再对数据进行读写,在它释放锁之前任何人都不能对其数据进行操作,直到前面一个人把锁释放后下一个人数据加锁才可对数据进行加锁,然后才可以对数据进行操作,一般数据库本身锁的机制都是基于悲观锁的机制实现的;
特点:可以完全保证数据的独占性和正确性,因为每次请求都会先对数据进行加锁, 然后进行数据操作,最后再解锁,而加锁释放锁的过程会造成消耗,所以性能不高;
手动加悲观锁:
- 先读锁 LOCK tables test_db read;后释放锁 UNLOCK TABLES;
- 先写锁:LOCK tables test_db WRITE;后释放锁 UNLOCK TABLES;
3、什么是乐观锁?
乐观锁是对于数据冲突保持一种乐观态度,操作数据时不会对操作的数据进行加锁(这使得多个任务可以并行的对数据进行操作),只有到数据提交的时候才通过一种机制来验证数据是否存在冲突(一般实现方式是通过加版本号然后进行版本号的对比方式实现);
特点:乐观锁是一种并发类型的锁,其本身不对数据进行加锁通而是通过业务实现锁的功能,不对数据进行加锁就意味着允许多个请求同时访问数据,同时也省掉了对数据加锁和解锁的过程,这种方式因为节省了悲观锁加锁的操作,所以可以一定程度的的提高操作的性能,不过在并发非常高的情况下,会导致大量的请求冲突,冲突导致大部分操作无功而返而浪费资源,所以在高并发的场景下,乐观锁的性能却反而不如悲观锁。
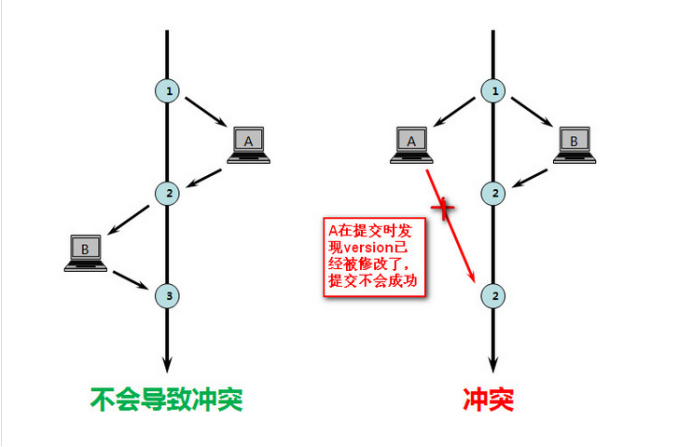
乐观锁实现形式,示意图如上,简单示例即
有表 A 如下:
| id | name | version |
|---|---|---|
| 1 | zhangsan | 1 |
现在有两个请求同时操作表 A
操作 1 先查询出需要检索的数据为:
id name version 1 zhangsan 1 操作 2 也查询出需要检索的数据为:
id name version 1 zhangsan 1 操作 1 把 name 字段数据修改成 lisi 比操作 2 先提交;
此时提交操作 1 会把之前查询到的 version 与现在的数据的 version 进行比较,版本相同则可以提交,版本不同则视为数据过期:
update A set Name=lisi, version=version+1 where ID=#{id} and version=#{version}此时数据库变成了如下:
id name version 1 lisi 2 那么,最后操作 2 修改了数据来提交的时候是以操作 1 同样的方式,当然最后肯定不能提交成功,因为他手里的版本号和现在数据库里的版本号不匹配;
synchronized
在类普通方法上锁实例(即 this ),影响同一个实例所有带锁的方法;在类静态方法上锁类(即 xx.class )
Java 提供的一种内置锁机制,其底层是基于 JVM 的 监视器锁(Monitor Lock) 实现的。具体来说:
- 每个对象在 JVM 中都有一个与之关联的监视器锁(Monitor),当线程进入
synchronized块时,会尝试获取该对象的监视器锁。 - 如果锁已经被其他线程持有,则当前线程会被阻塞,直到锁被释放。
synchronized的实现依赖于操作系统的底层互斥锁(Mutex Lock),这可能会导致线程的上下文切换和内核态切换,性能开销较大。
特点:
- 简单易用,语法层面直接支持。
- 锁的获取和释放由 JVM 自动管理。
- 不支持高级功能(如尝试获取锁、超时获取锁、可中断获取锁等)。
java.util.concurrent.locks.ReentrantLock
可重入锁,基于 AQS(AbstractQueuedSynchronizer 实现。
特点:
- 显式锁:需要手动调用
lock()和unlock()方法。 - 支持高级功能:
- 可重入性 :同一线程可以多次获取同一把锁。
- 公平锁/非公平锁 :可以选择是否按照请求顺序分配锁。
- 可中断获取锁 :线程可以在等待锁的过程中被中断。
- 尝试获取锁 :支持尝试获取锁(
tryLock())或带超时的获取锁(tryLock(long timeout, TimeUnit unit))。
- 更高的灵活性和性能优化空间。
更进一步可以实现锁池(即初始化n个锁,根据某个值获取锁)
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;
// 1. 定义锁的数量
private static final int NUMBER_OF_LOCKS = 16;
// 2. 创建一个固定大小的锁数组
private final Lock[] locks = new Lock[NUMBER_OF_LOCKS];
// 3. 在构造方法中初始化锁
for (int i = 0; i < NUMBER_OF_LOCKS; i++) {
locks[i] = new ReentrantLock();
}
// 4. 使用锁
Lock lock = getLockFor(tagName);
lock.lock(); // 加锁
try {
// --- 临界区 ---
// ...
// 如双重检查逻辑
} finally {
lock.unlock(); // 保证在 finally 块中解锁
}
/**
* 根据给定的 key(这里是标签名)获取对应的锁。
* @param key 标签名
* @return n个锁中的一个
*/
private Lock getLockFor(String key) {
// 使用 key 的哈希值和取模运算来决定使用哪个锁
int lockIndex = Math.abs(key.hashCode() % NUMBER_OF_LOCKS);
return locks[lockIndex];
}java.util.concurrent.ConcurrentHashMap
ConcurrentHashMap<String, Object>.computeIfAbsent(name, k -> new Object());
synchronized (lock) {};
实现细粒度锁控制,注意加锁导致的内存溢出,适时进行 Remove
com.google.common.util.concurrent.Striped
java.util.concurrent.locks.Lock
Google 的 Guava 库提供了一个完美的工具来解决上述问题,名为 Striped。它是一种更高明的“分段锁”,可以提供细粒度的锁定,同时避免了内存泄漏的问题。
private final Striped<Lock> locks = Striped.lazyWeakLock(16);
Lock lock = locks.get(key);
lock.lock();
lock.unlock();什么是可重入性,为什么需要可重入性?
可重入(Reentrant) 是指一个线程可以多次获取同一个锁而不会导致死锁的能力。换句话说,当一个线程已经持有某个锁时,它可以在不释放锁的情况下再次获取该锁。这种特性被称为 可重入性。
1. 为什么需要可重入性?
假如锁不可重入,以下场景会导致问题:
示例代码:
public class Example {
public synchronized void methodA() {
System.out.println("Method A is running.");
methodB(); // 调用另一个同步方法
}
public synchronized void methodB() {
System.out.println("Method B is running.");
}
}- 如果锁不可重入,线程在执行
methodA时已经持有当前对象的锁。 - 当
methodA调用methodB时,线程会尝试再次获取同一个锁,但由于锁已经被自己持有,线程会被阻塞,导致死锁。
因此,Java 的锁机制(无论是 synchronized 还是 ReentrantLock)都支持可重入性,以避免这种问题。
2. 可重入的工作原理
可重入锁的核心思想是:每个锁都有一个计数器(Hold Count),用来记录当前线程获取锁的次数。
工作流程:
- 第一次获取锁:
- 线程成功获取锁后,计数器加 1。
- 再次获取锁:
- 如果同一线程再次尝试获取锁,计数器继续递增,而不是阻塞线程。
- 释放锁:
- 每次调用
unlock()或退出synchronized块时,计数器减 1。 - 当计数器归零时,锁被完全释放,其他线程可以获取锁。
- 每次调用
3. synchronized 的可重入性
synchronized 是 Java 内置的可重入锁。它的可重入性是由 JVM 自动管理的,无需开发者手动干预。
示例代码:
public class SynchronizedExample {
public synchronized void methodA() {
System.out.println("Method A is running.");
methodB(); // 调用另一个同步方法
}
public synchronized void methodB() {
System.out.println("Method B is running.");
}
public static void main(String[] args) {
SynchronizedExample example = new SynchronizedExample();
new Thread(example::methodA).start();
}
}输出结果:
Method A is running.
Method B is running.- 线程进入
methodA时获取了锁,计数器为 1。 - 调用
methodB时,线程再次获取同一个锁,计数器变为 2。 - 执行完成后,计数器逐渐减为 0,锁被释放。
4. ReentrantLock 的可重入性
ReentrantLock 是显式锁(Explicit Lock, 是指需要开发者手动获取和释放的锁,而 Java 的内置锁机制 synchronized 自动管理),也需要支持可重入性。它的实现基于 AQS(AbstractQueuedSynchronizer),通过维护一个计数器来实现可重入。
示例代码:
import java.util.concurrent.locks.ReentrantLock;
public class ReentrantLockExample {
private final ReentrantLock lock = new ReentrantLock();
public void methodA() {
lock.lock(); // 第一次获取锁
try {
System.out.println("Method A is running.");
methodB(); // 调用另一个同步方法
} finally {
lock.unlock(); // 第一次释放锁
}
}
public void methodB() {
lock.lock(); // 第二次获取锁
try {
System.out.println("Method B is running.");
} finally {
lock.unlock(); // 第二次释放锁
}
}
public static void main(String[] args) {
ReentrantLockExample example = new ReentrantLockExample();
new Thread(example::methodA).start();
}
}输出结果:
Method A is running.
Method B is running.- 在
methodA中,线程第一次调用lock.lock(),计数器变为 1。 - 在
methodB中,线程第二次调用lock.lock(),计数器变为 2。 - 每次调用
lock.unlock()时,计数器减 1,直到归零时锁被完全释放。
5. 可重入性的优点
避免死锁:
同一线程可以多次获取同一个锁,而不会因为重复获取导致阻塞。提高代码灵活性:
支持嵌套调用同步方法或代码块,简化多层逻辑的开发。减少复杂性:
开发者无需担心同一锁的多次获取问题,降低了出错的可能性。
6. 非可重入锁的问题
如果锁不可重入,以下代码会导致死锁:
public class NonReentrantLockExample {
private final Object lock = new Object();
public void methodA() {
synchronized (lock) {
System.out.println("Method A is running.");
methodB(); // 调用另一个同步方法
}
}
public void methodB() {
synchronized (lock) {
System.out.println("Method B is running.");
}
}
public static void main(String[] args) {
NonReentrantLockExample example = new NonReentrantLockExample();
new Thread(example::methodA).start();
}
}- 如果
synchronized不支持可重入性,线程在methodA中已经持有锁,调用methodB时会再次尝试获取锁,但无法成功,从而导致死锁。
7. 总结
- 可重入性 是指同一线程可以多次获取同一个锁而不会死锁的能力。
synchronized和ReentrantLock都支持可重入性,分别通过 JVM 的内置机制和 AQS 的计数器实现。- 可重入性避免了嵌套调用时的死锁问题,提高了代码的灵活性和安全性。
Java Thread 的 6 种状态中某几种是基于 synchronized 实现转换的,这是不是说 ReentrantLock 不会出现其中的某几种状态
1. 线程的几种状态
在 Java 中,线程的状态由 Thread.State 枚举定义,包括以下几种:
NEW 线程对象被创建但尚未启动(即未调用
start()方法)。RUNNABLE 线程正在 JVM 中运行,可能在执行代码,也可能在等待操作系统资源(如 CPU 时间片)。
BLOCKED 线程试图获取一个由其他线程持有的监视器锁(即
synchronized锁),但未能成功,因此处于阻塞状态。WAITING 线程无限期地等待另一个线程显式唤醒它。常见的场景包括:
- 调用
Object.wait()。 - 调用
Thread.join()。 - 使用
LockSupport.park()。
- 调用
TIMED_WAITING 线程在指定的时间内等待另一个线程唤醒它。常见的场景包括:
- 调用
Object.wait(long timeout)。 - 调用
Thread.sleep(long millis)。 - 调用
Thread.join(long millis)。 - 使用
LockSupport.parkNanos()或LockSupport.parkUntil()。
- 调用
TERMINATED
线程已完成执行或因异常终止。
2. synchronized 和线程状态的关系
synchronized 是基于 JVM 的监视器锁(Monitor Lock)实现的,因此它会直接影响线程的状态,尤其是 BLOCKED 和 WAITING 状态:
- BLOCKED:当线程尝试获取一个已被其他线程持有的
synchronized锁时,线程会进入 BLOCKED 状态。 - WAITING:当线程在持有
synchronized锁的情况下调用Object.wait()时,线程会释放锁并进入 WAITING 状态,直到被其他线程通过notify()或notifyAll()唤醒。
3. ReentrantLock 和线程状态的关系
ReentrantLock 是基于 AQS(AbstractQueuedSynchronizer)实现的,它不依赖于 JVM 的监视器锁,因此不会直接导致线程进入 BLOCKED 状态。然而,ReentrantLock 仍然可以通过其内部机制影响线程的状态:
RUNNABLE 和 TIMED_WAITING
当线程尝试获取
ReentrantLock并调用tryLock(long timeout, TimeUnit unit)时,如果锁不可用且超时时间未到,线程会进入 TIMED_WAITING 状态。WAITING
当线程使用
ReentrantLock的条件变量(Condition)调用await()时,线程会释放锁并进入 WAITING 状态,类似于Object.wait()。BLOCKED
ReentrantLock不会导致线程进入 BLOCKED 状态,因为它的锁获取机制是基于 AQS 的队列管理,而不是 JVM 的监视器锁。如果线程无法获取锁,它会被加入到 AQS 的等待队列中,并进入 WAITING 或 TIMED_WAITING 状态,而不是 BLOCKED 状态。
4. 总结:ReentrantLock 是否会出现某些状态?
以下是 synchronized 和 ReentrantLock 对线程状态的影响对比:
| 线程状态 | synchronized 是否出现 | ReentrantLock 是否出现 | 备注 |
|---|---|---|---|
| NEW | 是 | 是 | 线程的初始状态,与锁无关。 |
| RUNNABLE | 是 | 是 | 线程正在运行或等待 CPU 资源。 |
| BLOCKED | 是 | 否 | synchronized 会导致线程进入 BLOCKED 状态,ReentrantLock 不会。 |
| WAITING | 是 | 是 | synchronized 的 wait() 和 ReentrantLock 的 await() 都会导致。 |
| TIMED_WAITING | 是 | 是 | synchronized 的 wait(long) 和 ReentrantLock 的 tryLock() 都会导致。 |
| TERMINATED | 是 | 是 | 线程结束状态,与锁无关。 |
5. 为什么 ReentrantLock 不会导致 BLOCKED 状态?
这是因为 ReentrantLock 的设计与 synchronized 不同:
synchronized直接依赖 JVM 的监视器锁,当线程无法获取锁时,JVM 会将线程标记为 BLOCKED 状态。ReentrantLock使用 AQS 的队列来管理等待线程。当线程无法获取锁时,它会被加入到 AQS 的等待队列中,并进入 WAITING 或 TIMED_WAITING 状态,而不是 BLOCKED 状态。
6. 实际意义
虽然 ReentrantLock 不会导致 BLOCKED 状态,但这并不意味着它的性能一定优于 synchronized。两者的性能差异取决于具体的使用场景:
- 在低竞争场景下,
synchronized的性能通常更好,因为它是 JVM 内置的,优化程度更高。 - 在高竞争场景下,
ReentrantLock提供了更多的灵活性和功能(如公平锁、可中断锁等),可能更适合复杂的需求。
7. 结论
ReentrantLock不会导致线程进入 BLOCKED 状态,因为它不依赖 JVM 的监视器锁。ReentrantLock仍然会导致线程进入 WAITING 和 TIMED_WAITING 状态,尤其是在使用条件变量(Condition)时。synchronized和ReentrantLock都会影响线程的状态,但它们的实现机制不同,因此对线程状态的影响也有所不同。
什么是显示锁
显式锁(Explicit Lock) 是指需要开发者手动获取和释放的锁,与 Java 的内置锁机制 synchronized 不同。显式锁提供了更高的灵活性和控制能力,适用于复杂的并发场景。
1. 什么是显式锁?
显式锁是通过 java.util.concurrent.locks.Lock 接口及其具体实现类(如 ReentrantLock)来管理的一种锁机制。开发者需要显式地调用 lock() 方法获取锁,并在操作完成后调用 unlock() 方法释放锁。
示例代码:
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;
public class ExplicitLockExample {
private final Lock lock = new ReentrantLock();
public void performTask() {
lock.lock(); // 手动获取锁
try {
System.out.println("Lock acquired, performing task...");
// 模拟任务执行
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
lock.unlock(); // 手动释放锁
}
}
public static void main(String[] args) {
ExplicitLockExample example = new ExplicitLockExample();
new Thread(example::performTask).start();
new Thread(example::performTask).start();
}
}- 在上述代码中,
lock.lock()和lock.unlock()是显式调用的。 - 如果开发者忘记调用
unlock(),可能会导致死锁或其他问题。
2. 显式锁 vs 内置锁(synchronized)
以下是显式锁和内置锁的主要区别:
| 特性 | synchronized | 显式锁(Lock) |
|---|---|---|
| 获取和释放锁的方式 | 自动管理(进入同步块时自动获取锁,退出时自动释放锁)。 | 手动管理(需要显式调用 lock() 和 unlock())。 |
| 灵活性 | 较低 | 较高 |
| 可中断获取锁 | 不支持 | 支持 |
| 尝试获取锁 | 不支持 | 支持(tryLock()) |
| 超时获取锁 | 不支持 | 支持(tryLock(long timeout, TimeUnit unit)) |
| 公平锁 | 不支持 | 支持 |
| 条件变量 | 使用 wait()/notify() | 使用 Condition 提供更灵活的条件控制 |
3. 显式锁的优势
显式锁相比 synchronized 提供了更多的功能和灵活性,适用于复杂的并发场景:
(1)可中断获取锁
线程在等待锁的过程中可以被中断,避免长时间阻塞。
lock.lockInterruptibly();
try {
// 执行任务
} finally {
lock.unlock();
}(2)尝试获取锁
线程可以尝试获取锁,如果无法立即获取,则可以选择放弃或采取其他操作。
if (lock.tryLock()) {
try {
// 执行任务
} finally {
lock.unlock();
}
} else {
// 处理无法获取锁的情况
}(3)带超时的获取锁
线程可以在指定时间内尝试获取锁,超时后可以选择放弃。
if (lock.tryLock(5, TimeUnit.SECONDS)) {
try {
// 执行任务
} finally {
lock.unlock();
}
} else {
// 超时处理
}(4)公平锁
公平锁会按照线程请求锁的顺序分配锁,避免饥饿现象。
private final Lock fairLock = new ReentrantLock(true); // true 表示公平锁(5)多条件变量
Condition 允许为同一个锁创建多个条件变量,用于更精细的线程协调。
private final Lock lock = new ReentrantLock();
private final Condition conditionA = lock.newCondition();
private final Condition conditionB = lock.newCondition();
public void awaitConditionA() throws InterruptedException {
lock.lock();
try {
conditionA.await();
} finally {
lock.unlock();
}
}
public void signalConditionA() {
lock.lock();
try {
conditionA.signal();
} finally {
lock.unlock();
}
}4. 显式锁的注意事项
虽然显式锁功能强大,但也需要注意以下几点:
必须手动释放锁: 忘记调用
unlock()会导致死锁或其他问题。因此,通常将unlock()放在finally块中。性能开销: 显式锁的灵活性带来了额外的性能开销,在低竞争场景下可能不如
synchronized高效。复杂性增加: 显式锁需要开发者手动管理锁的生命周期,增加了代码的复杂性。
5. 总结
- 显式锁 是一种需要开发者手动获取和释放的锁机制,通过
Lock接口实现(如ReentrantLock)。 - 它提供了比
synchronized更高的灵活性和功能(如可中断获取锁、尝试获取锁、超时获取锁等)。 - 显式锁适用于复杂的并发场景,但在简单场景下,
synchronized更加简洁高效。
concurrent.ConcurrentHashMap相对于hashmap是如何实现线程安全的
Gemini2.5 pro
ConcurrentHashMap 通过采用分段锁(在Java 8之前)和在Java 8及以后版本中更为精细的基于CAS(比较并交换)操作和synchronized的节点锁机制,来实现相对于HashMap的线程安全性。HashMap本身并非线程安全,在并发环境下对其进行修改操作可能导致数据不一致甚至死循环。
HashMap 的非线程安全性
HashMap 在多线程环境下的主要问题体现在以下两个方面:
并发写操作导致数据丢失:如果多个线程同时尝试向同一个桶(bucket)中添加元素,由于没有同步机制,后一个线程的写入操作可能会覆盖前一个线程的写入,导致数据丢失。
并发
put操作可能引发死循环:这是HashMap在并发场景下最严重的问题,尤其是在需要扩容(resize)时。当HashMap的容量不足时,会创建一个新的、更大的数组,并将旧数组中的所有元素重新计算哈希值并放入新数组中。在Java 7及更早版本中,这个转移过程采用了头插法,在并发环境下,多个线程同时进行扩容操作时,可能会导致链表中的节点形成环形结构。这样,在后续的get操作遍历这个链表时,就会陷入无限循环,导致CPU占用率飙升。
ConcurrentHashMap 的线程安全实现机制
为了解决 HashMap 的并发问题,ConcurrentHashMap 采用了更为复杂的内部结构和算法,其实现方式在Java 8前后有显著不同。
Java 7 及更早版本的实现:分段锁(Segment Locking)
在早期的版本中,ConcurrentHashMap 的内部由一个Segment数组构成。每个Segment本身都是一个类似于HashMap的结构,并且拥有自己独立的锁(ReentrantLock)。
- 分而治之:整个
ConcurrentHashMap被分成多个Segment。当一个线程需要对某个键值对进行写操作时,它首先需要确定这个键值对属于哪个Segment,然后只需要获取对应Segment的锁,而不需要锁定整个Map。 - 并发度:锁的粒度是
Segment级别的,因此,不同Segment上的写操作可以并行执行,互不影响。Segment的数量决定了并发度(concurrency level),默认为16。这意味着在理想情况下,最多可以有16个线程同时对ConcurrentHashMap进行写操作。 - 读操作:读操作(如
get)在大多数情况下不需要加锁,因为其内部使用的volatile关键字保证了内存可见性,可以立即看到其他线程对Map的修改。
这种分段锁的设计,虽然极大地提高了并发性能,但其结构相对复杂,并且在某些场景下,如果哈希冲突集中在少数几个Segment上,仍然会存在较激烈的锁竞争。
Java 8 及以后版本的实现:CAS + synchronized
从Java 8开始,ConcurrentHashMap的实现被完全重构,放弃了Segment分段锁的设计,转而采用了更细粒度的锁机制,结合了无锁的CAS算法和synchronized关键字。
其内部结构更接近于HashMap,由一个Node数组构成,每个数组元素是一个桶的头节点。
无锁的读操作和CAS更新:
get操作完全不加锁,通过volatile关键字保证了Node数组和Node中关键属性的内存可见性。- 对于一些简单的写操作,比如向一个空的桶中添加第一个节点,或者更新某个节点的值,会优先使用CAS(Compare-And-Swap)操作。CAS是一种乐观锁技术,它会先比较内存中的值是否为预期值,如果是,则更新它。这个过程是原子性的,避免了加锁带来的开销。
synchronized锁定的细粒度化:- 当CAS操作失败,或者需要在一个已经存在节点的桶中进行添加或删除操作时(即哈希冲突时),
ConcurrentHashMap会使用synchronized关键字来锁定该桶的头节点。 - 锁粒度极小:锁定的只是发生冲突的那个桶的头节点,而不是整个
Map或者一个大的Segment。这意味着只有当多个线程试图同时修改同一个桶时,才会发生锁竞争。不同桶之间的操作完全可以并行执行,从而极大地提高了并发性能。 - 当桶中的链表长度超过一定阈值(默认为8)时,链表会转换成红黑树,以优化查询性能。对红黑树的修改同样是通过
synchronized锁定头节点来保证线程安全。
- 当CAS操作失败,或者需要在一个已经存在节点的桶中进行添加或删除操作时(即哈希冲突时),
安全的并发扩容:
- 扩容操作也变得更加智能。当需要扩容时,可以由多个线程协作完成。每个线程会负责转移一部分桶的数据到新的数组中,而不是由单个线程完成所有工作。这大大缩短了扩容所需的时间,并减少了其间对
Map性能的影响。
- 扩容操作也变得更加智能。当需要扩容时,可以由多个线程协作完成。每个线程会负责转移一部分桶的数据到新的数组中,而不是由单个线程完成所有工作。这大大缩短了扩容所需的时间,并减少了其间对
总结
| 特性 | HashMap | ConcurrentHashMap (Java 8+) |
|---|---|---|
| 线程安全 | ❌ 非线程安全 | ✅ 线程安全 |
| 锁机制 | 无 | synchronized + CAS (比较并交换) |
| 锁粒度 | - | 节点级别(桶的头节点),非常细 |
| 并发写 | 可能导致数据丢失或死循环 | 安全,不同桶的操作可完全并行 |
| 并发读 | 可能读到不一致的数据 | 无锁,通过 volatile 保证可见性 |
| 扩容 | 并发环境下可能导致死循环 | 安全,可由多线程协作完成 |
| null值 | 允许null键和null值 | ❌ 不允许null键和null值 |
Qwen3
ConcurrentHashMap 相比 HashMap 实现线程安全的关键在于其并发控制机制,不同 JDK 版本的实现方式有显著差异:
JDK 1.7 的分段锁机制
数据结构:采用 Segment 数组 + HashEntry 数组 + 链表 的结构,将整个哈希表划分为多个独立片段(Segment),每个 Segment 本质上是一个小型哈希表,通过继承
ReentrantLock实现锁功能。- 锁粒度:每个 Segment 独立加锁,允许多个线程同时访问不同 Segment 的数据,减少锁竞争。
- 线程安全实现:
- 写操作:通过
ReentrantLock锁定对应 Segment,确保同一 Segment 的写操作串行化。 - 读操作:利用 HashEntry 的
volatile变量(如value和next)保证内存可见性,读操作无需加锁。
- 写操作:通过
扩容机制:
- Segment 数组初始化后不再扩容,仅扩容 HashEntry 数组。扩容时,每个 Segment 独立完成数据迁移,避免全局锁。
JDK 1.8 的 CAS + synchronized 优化
数据结构:采用 Node 数组 + 链表 + 红黑树 的组合,链表在长度超过 8 且数组长度 ≥64 时转为红黑树,提升查询效率(O(n) → O(log n))。
线程安全实现:
- CAS 无锁化操作:
- 插入新节点时,优先通过 CAS 原子操作尝试修改头节点,失败则进入锁机制。
- 使用
Unsafe类的 CAS 方法(如compareAndSwapObject)更新数组元素,减少锁的使用。
- synchronized 细粒度锁:
- 当 CAS 冲突或扩容时,仅对当前链表或红黑树的头节点加锁,而非整个数组,进一步缩小锁的粒度。
- volatile 保证可见性:Node 节点的
val和next字段用volatile修饰,确保多线程下的内存可见性。
- CAS 无锁化操作:
扩容优化:
- 支持多线程协作扩容,通过
sizeCtl和transferIndex协调任务分配,避免单线程扩容的性能瓶颈。 - 扩容时插入新节点采用尾插法,避免 JDK 1.7 中头插法导致的死循环问题。
- 支持多线程协作扩容,通过
size 计算:
- 通过
baseCount和CounterCell[]数组记录元素数量,结合 CAS 更新,避免全局锁,最终通过sumCount()汇总结果。
- 通过
关键区别与优化点
| 特性 | JDK 1.7 ConcurrentHashMap | JDK 1.8 ConcurrentHashMap |
|---|---|---|
| 数据结构 | Segment 数组 + HashEntry 数组 + 链表 | Node 数组 + 链表/红黑树 |
| 锁机制 | Segment 分段锁(ReentrantLock) | CAS + synchronized(锁头节点) |
| 扩容效率 | 单线程扩容,锁粒度大 | 多线程协作扩容,减少阻塞 |
| 查询性能 | 链表 O(n) | 红黑树 O(log n) |
| size() 实现 | 通过分段计数器 + 尝试加锁汇总 | CAS 更新计数,直接返回结果 |
线程安全的核心保障
- 避免死循环:JDK 1.8 使用尾插法替代头插法,解决扩容时链表成环的问题。
- CAS 降低锁竞争:通过原子操作更新节点,仅在冲突时加锁,减少同步开销。
- volatile 保证可见性:Node 的
val和next字段用volatile修饰,确保多线程间数据可见。 - 红黑树优化查询:高冲突场景下,红黑树显著提升查询效率。
示例说明
- JDK 1.7:悲观锁,多线程向不同 Segment 插入数据时,各自获取独立锁,互不阻塞;同一 Segment 的写操作需竞争锁。
- JDK 1.8:乐观锁,多线程向同一链表插入数据时,CAS 优先尝试插入,失败后再加锁,减少锁使用频率。
总结
ConcurrentHashMap 通过分段锁(JDK 1.7)或 CAS + synchronized(JDK 1.8)实现了高效的线程安全,兼顾性能与安全性。JDK 1.8 的改进(如红黑树、尾插法、CAS 优化)使其在高并发场景下表现更优。