代码纠错研究
代码纠错研究
目标
实现大模型自动纠错,不在乎代码只在乎结果。
问题的提出
在进行基于大模型的智能表格处理助手的项目开发中,我们需要根据表格的操作步骤描述序列,逐步生成对应的代码片段,依次分步执行得到最终结果。
在该过程中,由于大模型能力的局限性,有一定概率导致代码出现错误,包括但不限于语法错误、逻辑错误、运行时错误等,故而,在假设步骤无误的前提下,实现基于大模型的代码纠错。
调研情况
这是导提出的研究点,但我在实际调研过程中,发现该点有一个宏观的工作:自动程序修复 ARP,并有一个最近几年新成立的会议:program-repair.org
我认为如果是结合我的现有工作来说,该点相对大材小用,且需求不是那么符合,ARP 一般是针对已有的大型工程代码文件,而我们的需求只是对一小段出错的代码进行纠正,目标只是最终得到结果,与其只在反向优化,不如正反结合,提升生成代码的正确性+实现代码的纠错。
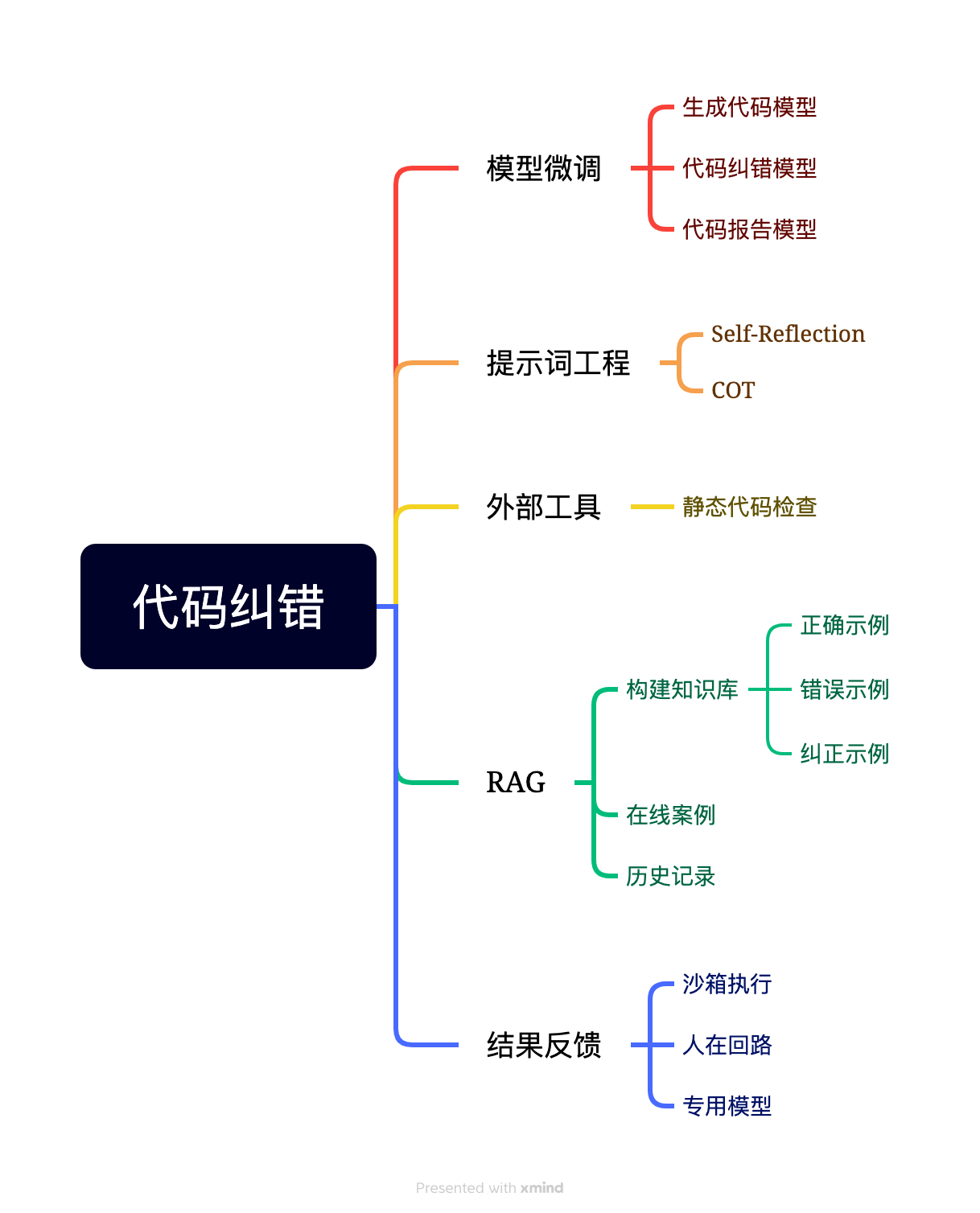
可行方向
代码执行与反馈循环
动态执行与错误捕捉:将生成的代码在安全的沙箱环境中执行,捕捉运行时错误或异常。这些错误信息可以作为反馈,指导大模型纠正代码。(错误反馈,最容易实现)
测试用例验证与对比:通过预定义的测试用例或预期输出,验证代码的正确性。如果输出不符合预期,可以将差异信息反馈给模型,指导其进行修正。(该方法对于我们需求场景不太适用)
代码审查与建议系统
静态代码分析:利用静态代码分析工具检查语法错误、编码风格、潜在的逻辑漏洞和性能问题。这些工具可以提供详细的错误报告和改进建议,以此作为反馈指导大模型。(借助外部工具)
动态分析:在代码运行过程中收集性能数据,如执行时间、内存使用情况等,以识别潜在的性能瓶颈或资源泄漏。(该方法对于我们需求场景优先级不高)
多轮迭代与交互学习
用户反馈循环:鼓励用户对生成的代码进行评估和提供反馈,包括错误报告、性能建议或代码风格偏好。模型可以基于这些反馈进行代码的迭代改进。(引入用户反馈,人在回路的概念)
模型自适应学习:让模型在生成和修正代码的过程中持续学习,通过不断接收和处理新的代码样本,提高其生成代码的准确性和效率。(Prompt工程:在线学习/增量学习/RAG)
错误预测与预防
错误类型识别:训练模型识别常见的编程错误类型,如语法错误、逻辑错误、资源泄漏等,并在生成阶段主动避免这些错误。(微调生成模型,引入 reflection 机制)
代码质量评估:开发一套代码质量评估系统,用于评估代码的可读性、可维护性和效率,帮助模型学习编写更高质量的代码。(微调评估模型)
集成外部工具与服务
代码分析工具:集成静态代码分析器、动态分析器和调试器,为模型提供详细的错误报告和修正建议。
在线代码库与API服务:利用在线代码库和API服务,为模型提供丰富的代码示例和功能模块,帮助其生成更准确、更高效的代码。(引入外部知识)
安全与隐私保护
安全沙箱环境:在隔离的虚拟环境中运行代码,防止潜在的恶意代码或错误代码对系统造成损害。
隐私保护机制:确保在收集和处理用户反馈时,遵守数据保护法规,保护用户隐私。
持续优化与更新
模型更新与扩展:定期更新模型,引入新的编程语言、框架和最佳实践,以保持其在代码生成领域的先进性和准确性。
性能监控与调优:持续监控模型的性能,根据实际使用情况调整参数,优化生成代码的速度和质量。
方案总结