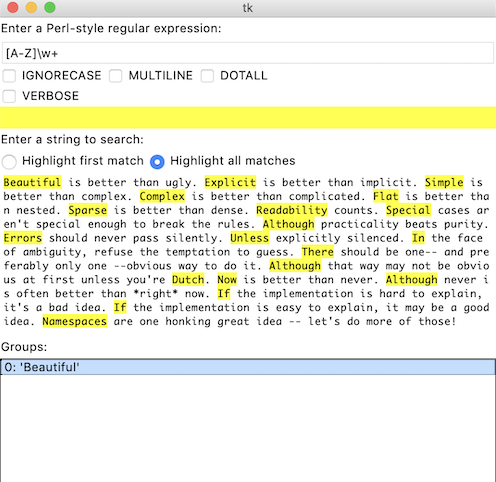
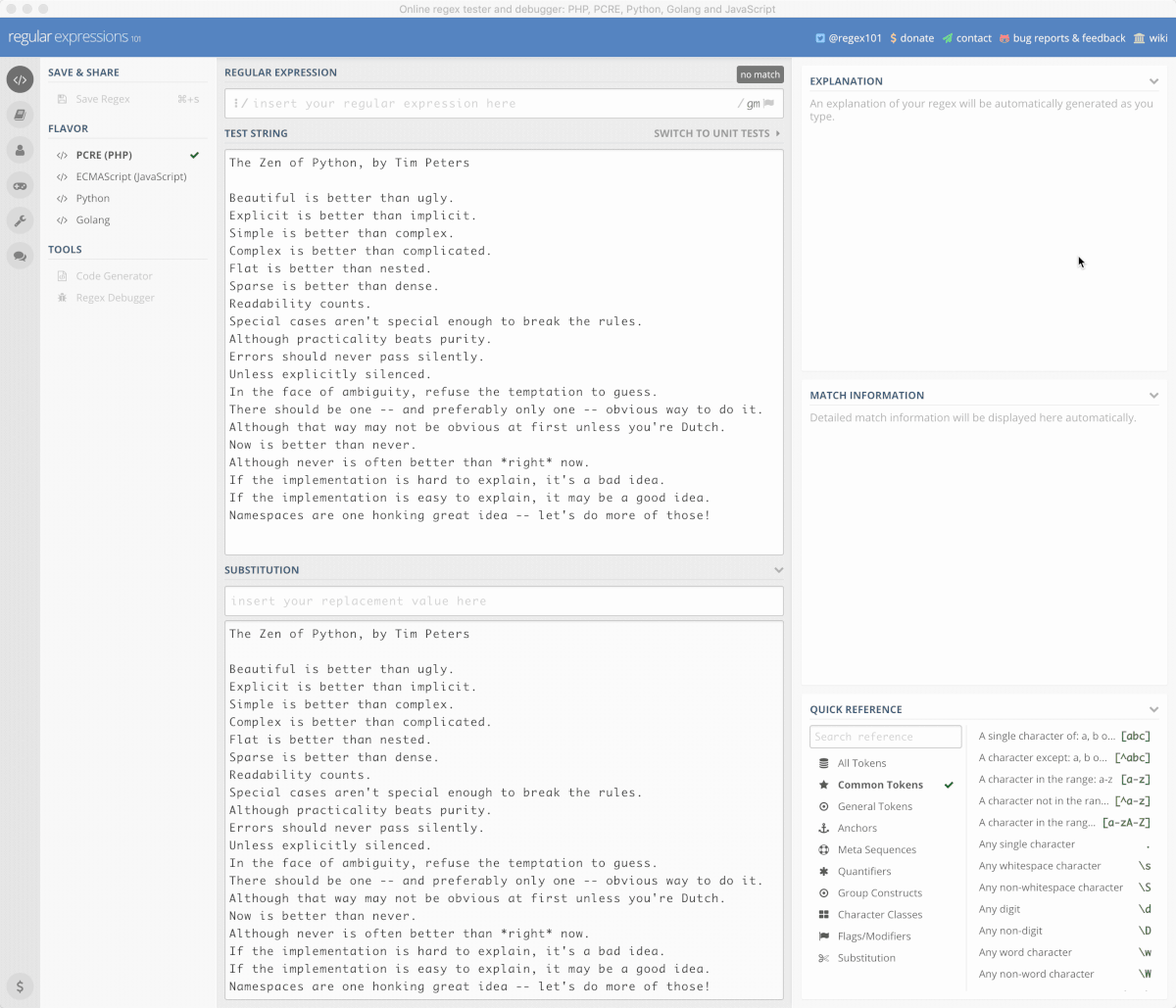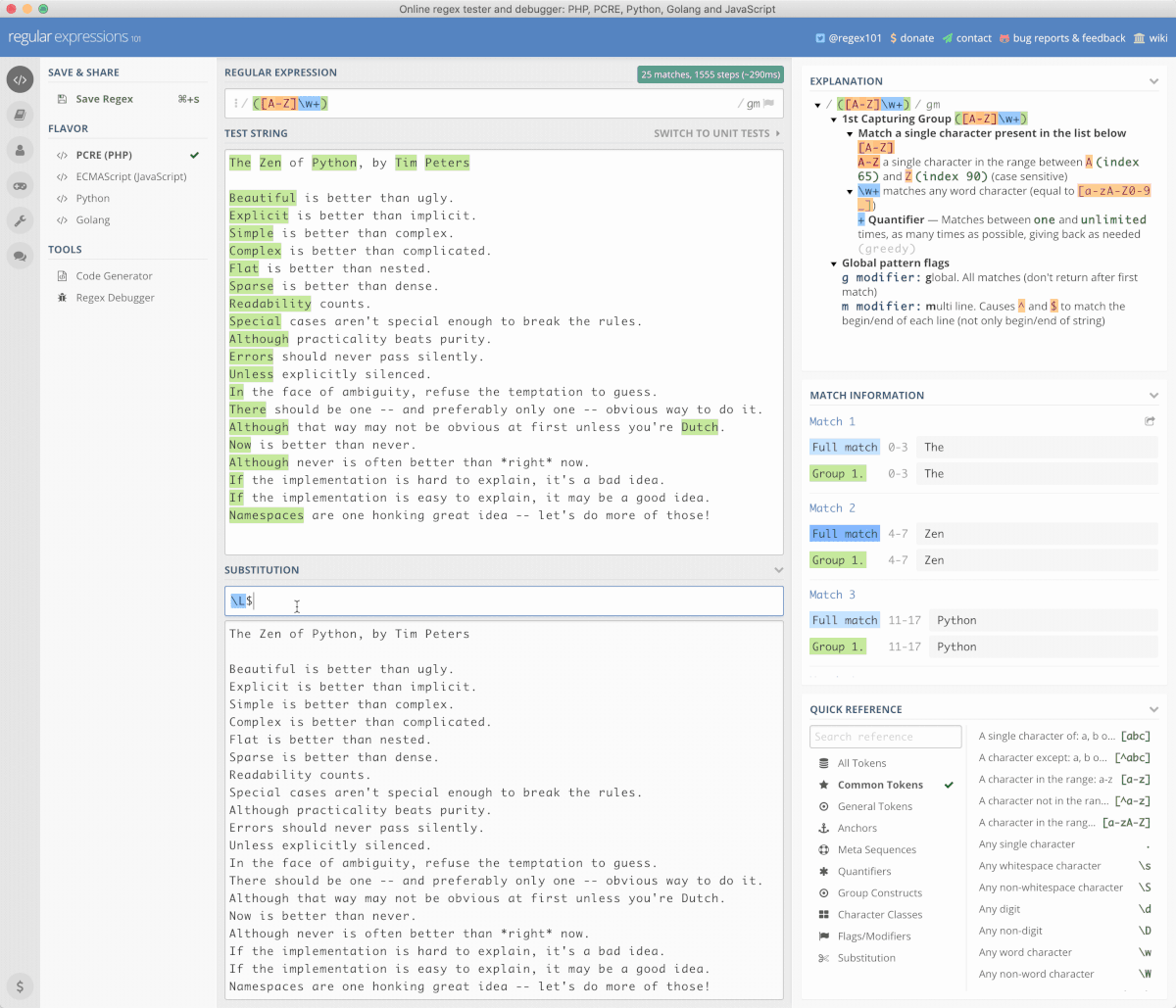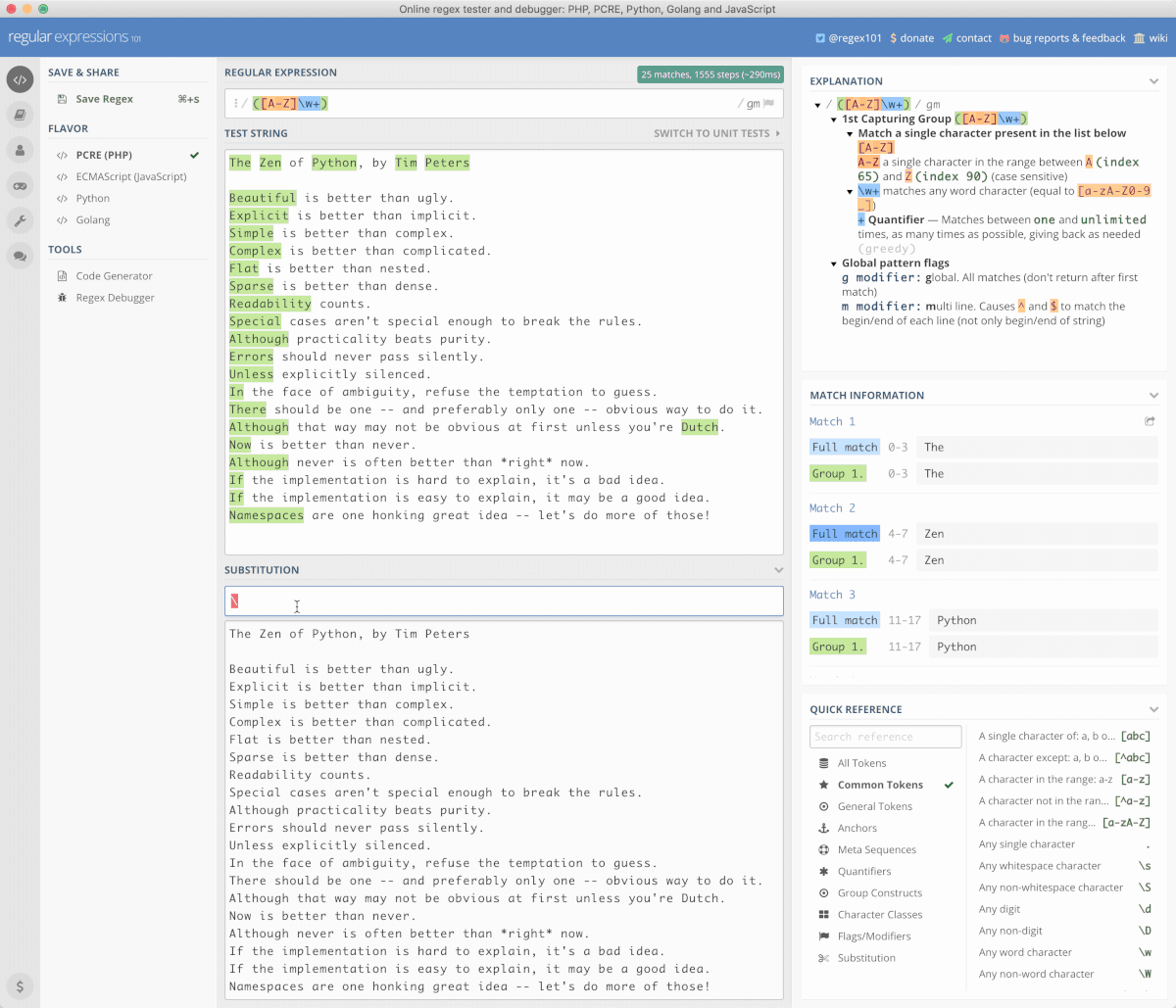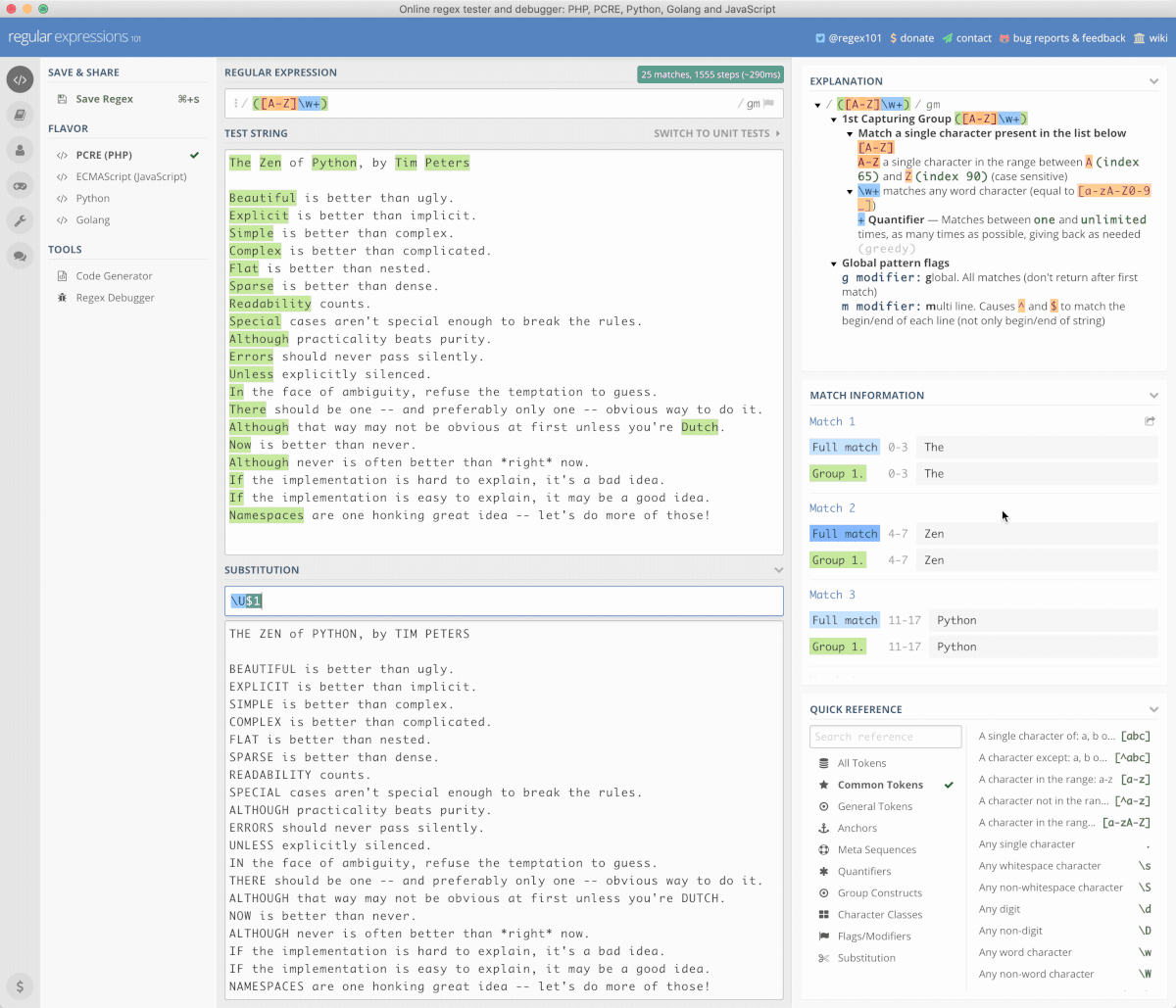
import re str = 'The white dog wears a black hat.' pttn = r'The (?:white|black) dog wears a (white|black) hat.' re.findall(pttn, str) # 只捕获了一处,也就是说只有一个值将来可以被引用
repl = r'The \1 dog wears a \1 hat.'# 之前的一处捕获,在替换时可被多次引用 書評 re.sub(pttn, repl, str)
# %load https://raw.githubusercontent.com/jezhiggins/eliza.py/master/eliza.py #---------------------------------------------------------------------- # eliza.py # # a cheezy little Eliza knock-off by Joe Strout # with some updates by Jeff Epler # hacked into a module and updated by Jez Higgins #----------------------------------------------------------------------
#---------------------------------------------------------------------- # translate: take a string, replace any words found in dict.keys() # with the corresponding dict.values() #---------------------------------------------------------------------- deftranslate(self,str,dict): words = str.lower().split() keys = dict.keys(); for i inrange(0,len(words)): if words[i] in keys: words[i] = dict[words[i]] return' '.join(words)
#---------------------------------------------------------------------- # respond: take a string, a set of regexps, and a corresponding # set of response lists; find a match, and return a randomly # chosen response from the corresponding list. #---------------------------------------------------------------------- defrespond(self,str): # find a match among keys for i inrange(0, len(self.keys)): match = self.keys[i].match(str) if match: # found a match ... stuff with corresponding value # chosen randomly from among the available options resp = random.choice(self.values[i]) # we've got a response... stuff in reflected text where indicated pos = resp.find('%') while pos > -1: num = int(resp[pos+1:pos+2]) resp = resp[:pos] + \ self.translate(match.group(num),gReflections) + \ resp[pos+2:] pos = resp.find('%') # fix munged punctuation at the end if resp[-2:] == '?.': resp = resp[:-2] + '.' if resp[-2:] == '??': resp = resp[:-2] + '?' return resp
#---------------------------------------------------------------------- # gReflections, a translation table used to convert things you say # into things the computer says back, e.g. "I am" --> "you are" #---------------------------------------------------------------------- gReflections = { "am" : "are", "was" : "were", "i" : "you", "i'd" : "you would", "i've" : "you have", "i'll" : "you will", "my" : "your", "are" : "am", "you've": "I have", "you'll": "I will", "your" : "my", "yours" : "mine", "you" : "me", "me" : "you" }
#---------------------------------------------------------------------- # gPats, the main response table. Each element of the list is a # two-element list; the first is a regexp, and the second is a # list of possible responses, with group-macros labelled as # %1, %2, etc. #---------------------------------------------------------------------- gPats = [ [r'I need (.*)', [ "Why do you need %1?", "Would it really help you to get %1?", "Are you sure you need %1?"]],
[r'Why don\'?t you ([^\?]*)\??', [ "Do you really think I don't %1?", "Perhaps eventually I will %1.", "Do you really want me to %1?"]],
[r'Why can\'?t I ([^\?]*)\??', [ "Do you think you should be able to %1?", "If you could %1, what would you do?", "I don't know -- why can't you %1?", "Have you really tried?"]],
[r'I can\'?t (.*)', [ "How do you know you can't %1?", "Perhaps you could %1 if you tried.", "What would it take for you to %1?"]],
[r'I am (.*)', [ "Did you come to me because you are %1?", "How long have you been %1?", "How do you feel about being %1?"]],
[r'I\'?m (.*)', [ "How does being %1 make you feel?", "Do you enjoy being %1?", "Why do you tell me you're %1?", "Why do you think you're %1?"]],
[r'Are you ([^\?]*)\??', [ "Why does it matter whether I am %1?", "Would you prefer it if I were not %1?", "Perhaps you believe I am %1.", "I may be %1 -- what do you think?"]],
[r'What (.*)', [ "Why do you ask?", "How would an answer to that help you?", "What do you think?"]],
[r'How (.*)', [ "How do you suppose?", "Perhaps you can answer your own question.", "What is it you're really asking?"]],
[r'Because (.*)', [ "Is that the real reason?", "What other reasons come to mind?", "Does that reason apply to anything else?", "If %1, what else must be true?"]],
[r'(.*) sorry (.*)', [ "There are many times when no apology is needed.", "What feelings do you have when you apologize?"]],
[r'Hello(.*)', [ "Hello... I'm glad you could drop by today.", "Hi there... how are you today?", "Hello, how are you feeling today?"]],
[r'I think (.*)', [ "Do you doubt %1?", "Do you really think so?", "But you're not sure %1?"]],
[r'(.*) friend (.*)', [ "Tell me more about your friends.", "When you think of a friend, what comes to mind?", "Why don't you tell me about a childhood friend?"]],
[r'Yes', [ "You seem quite sure.", "OK, but can you elaborate a bit?"]],
[r'(.*) computer(.*)', [ "Are you really talking about me?", "Does it seem strange to talk to a computer?", "How do computers make you feel?", "Do you feel threatened by computers?"]],
[r'Is it (.*)', [ "Do you think it is %1?", "Perhaps it's %1 -- what do you think?", "If it were %1, what would you do?", "It could well be that %1."]],
[r'It is (.*)', [ "You seem very certain.", "If I told you that it probably isn't %1, what would you feel?"]],
[r'Can you ([^\?]*)\??', [ "What makes you think I can't %1?", "If I could %1, then what?", "Why do you ask if I can %1?"]],
[r'Can I ([^\?]*)\??', [ "Perhaps you don't want to %1.", "Do you want to be able to %1?", "If you could %1, would you?"]],
[r'You are (.*)', [ "Why do you think I am %1?", "Does it please you to think that I'm %1?", "Perhaps you would like me to be %1.", "Perhaps you're really talking about yourself?"]],
[r'You\'?re (.*)', [ "Why do you say I am %1?", "Why do you think I am %1?", "Are we talking about you, or me?"]],
[r'I don\'?t (.*)', [ "Don't you really %1?", "Why don't you %1?", "Do you want to %1?"]],
[r'I feel (.*)', [ "Good, tell me more about these feelings.", "Do you often feel %1?", "When do you usually feel %1?", "When you feel %1, what do you do?"]],
[r'I have (.*)', [ "Why do you tell me that you've %1?", "Have you really %1?", "Now that you have %1, what will you do next?"]],
[r'I would (.*)', [ "Could you explain why you would %1?", "Why would you %1?", "Who else knows that you would %1?"]],
[r'Is there (.*)', [ "Do you think there is %1?", "It's likely that there is %1.", "Would you like there to be %1?"]],
[r'My (.*)', [ "I see, your %1.", "Why do you say that your %1?", "When your %1, how do you feel?"]],
[r'You (.*)', [ "We should be discussing you, not me.", "Why do you say that about me?", "Why do you care whether I %1?"]],
[r'Why (.*)', [ "Why don't you tell me the reason why %1?", "Why do you think %1?" ]],
[r'I want (.*)', [ "What would it mean to you if you got %1?", "Why do you want %1?", "What would you do if you got %1?", "If you got %1, then what would you do?"]],
[r'(.*) mother(.*)', [ "Tell me more about your mother.", "What was your relationship with your mother like?", "How do you feel about your mother?", "How does this relate to your feelings today?", "Good family relations are important."]],
[r'(.*) father(.*)', [ "Tell me more about your father.", "How did your father make you feel?", "How do you feel about your father?", "Does your relationship with your father relate to your feelings today?", "Do you have trouble showing affection with your family?"]],
[r'(.*) child(.*)', [ "Did you have close friends as a child?", "What is your favorite childhood memory?", "Do you remember any dreams or nightmares from childhood?", "Did the other children sometimes tease you?", "How do you think your childhood experiences relate to your feelings today?"]],
[r'(.*)\?', [ "Why do you ask that?", "Please consider whether you can answer your own question.", "Perhaps the answer lies within yourself?", "Why don't you tell me?"]],
[r'quit', [ "Thank you for talking with me.", "Good-bye.", "Thank you, that will be $150. Have a good day!"]],
[r'(.*)', [ "Please tell me more.", "Let's change focus a bit... Tell me about your family.", "Can you elaborate on that?", "Why do you say that %1?", "I see.", "Very interesting.", "%1.", "I see. And what does that tell you?", "How does that make you feel?", "How do you feel when you say that?"]] ]
#---------------------------------------------------------------------- # command_interface #---------------------------------------------------------------------- defcommand_interface(): print('Therapist\n---------') print('Talk to the program by typing in plain English, using normal upper-') print('and lower-case letters and punctuation. Enter "quit" when done.') print('='*72) print('Hello. How are you feeling today?')
s = '' therapist = eliza(); while s != 'quit': try: s = input('> ') except EOFError: s = 'quit' print(s) while s[-1] in'!.': s = s[:-1] print(therapist.respond(s))
if __name__ == "__main__": command_interface()
Therapist
---------
Talk to the program by typing in plain English, using normal upper-
and lower-case letters and punctuation. Enter "quit" when done.
========================================================================
Hello. How are you feeling today?