数据容器
在 Python 中,有个数据容器(Container)的概念。
其中包括字符串、由 range() 函数生成的等差数列、列表(List)、元组(Tuple)、集合(Set)、字典(Dictionary)。
这些容器,各有各的用处。其中又分为可变容器(Mutable)和不可变容器(Immutable)。可变的有列表、集合、字典;不可变的有字符串、range() 生成的等差数列、元组。集合,又分为 Set 和 Frozen Set;其中,Set 是可变的,Frozen Set 是不可变的。
字符串、由 range() 函数生成的等差数列、列表、元组是有序类型(Sequence Type),而集合与字典是无序的。
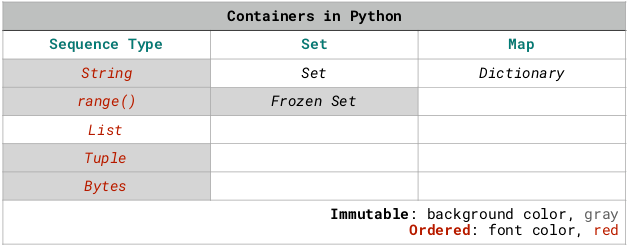
另外,集合没有重合元素。
迭代(Iterate)
数据容器里的元素是可以被迭代的(Iterable),它们其中包含的元素,可以被逐个访问,以便被处理。
对于数据容器,有一个操作符,in,用来判断某个元素是否属于某个容器。
由于数据容器的可迭代性,再加上这个操作符 in,在 Python 语言里写循环格外容易且方便(以字符串这个字符的容器作为例子):
1 | for c in 'Python': |
P
y
t
h
o
n
在 Python 出现之前,想要完成这样一个访问字符串中的每一个字符的循环,大抵上应该是这样的(比如 C 语言):
1 | # Written in C |
在 Python 中,简单的 for 循环,只需要指定一个次数就可以了,因为有 range() 这个函数:
1 | for i in range(10): |
0
1
2
3
4
5
6
7
8
9
即便是用比 C 更为 “现代” 一点的 JavaScript,也大抵上应该是这样的:
1 | var i; |
当然,有时候我们也需要比较复杂的计数器,不过,Python 也不只有 for 循环,还有 while 循环,在必要的时候可以写复杂的计数器。
列表(List)
列表和字符串一样,是个有序类型(Sequence Type)的容器,其中包含着有索引编号的元素。
列表中的元素可以是不同类型。不过,在解决现实问题的时候,我们总是倾向于创建由同一个类型的数据构成的列表。遇到由不同类型数据构成的列表,我们更可能做的是想办法把不同类型的数据分门别类地拆分出来,整理清楚 —— 这种工作甚至有个专门的名称与之关联:数据清洗。
列表的生成
生成一个列表,有以下几种方式:
1 | a_list = [] |
1 | a_list = [] |
[1, 2] has a length of 2.
[1, 2, 3, 4, 5, 6, 7, 8, 11] has a length of 9.
[1, 2, 4, 8, 16, 32, 64, 128] has a length of 8.
这最后一种方式颇为神奇:
1 | [2**x for x in range(8)] |
这种做法,叫做 **List Comprehension**。
Comprehend 这个词的意思除了 “理解” 之外,还有另外一个意思,就是 “包括、囊括” —— 这样的话,你就大概能理解这种做法为什么被称作 List Comprehension 了。中文翻译中,怎么翻译的都有,“列表生成器”、“列表生成式” 等等,都挺好。但是,被翻译成 “列表解析器”,就不太好了,给人的感觉是操作反了……
List comprehension 可以嵌套使用 for,甚至可以加上条件 if。官方文档里有个例子,是用来把两个元素并不完全相同的列表去同后拼成一个列表(下面稍作了改写):
1 | import random |
a_list comprehends 10 random numbers: [52, 34, 7, 96, 33, 79, 95, 18, 37, 46]
... and it has 5 even numbers: [52, 34, 96, 18, 46]
列表的操作符
列表的操作符和字符串一样,因为它们都是有序容器。列表的操作符有:
- 拼接:
+(与字符串不一样的地方是,不能用空格' '了)- 复制:
*- 逻辑运算:
in和not in,<、<=、>、>=、!=、==
而后两个列表也和两个字符串一样,可以被比较,即,可以进行逻辑运算;比较方式也跟字符串一样,从两个列表各自的第一个元素开始逐个比较,“一旦决出胜负马上停止”:
1 | from IPython.core.interactiveshell import InteractiveShell |
[1, 2, 3, 4, 5, 6, 4, 5, 6, 4, 5, 6]
True
False
根据索引提取列表元素
列表当然也可以根据索引操作,但由于列表是可变序列,所以,不仅可以提取,还可以删除,甚至替换。
1 | import random |
[77, 66, 79]
[77, 66, 79, 'L', 'Z', 'R', 77, 66, 79, 77, 66, 79]
L
[77, 66, 79, 'L', 'Z', 'R', 77, 66, 79, 77, 66, 79]
['R', 77, 66, 79, 77, 66, 79]
[77, 66, 79]
[79, 'L', 'Z', 'R']
[77, 66, 79, 'Z', 'R', 77, 66, 79, 77, 66, 79]
[77, 66, 79, 'Z', 'R', 77, 66, 79]
[77, 'a', 79, 2, 'R', 77, 66, 79]
需要注意的地方是:列表(List)是可变序列,而字符串(str)是不可变序列,所以,对字符串来说,虽然也可以根据索引提取,但没办法根据索引删除或者替换。
1 | s = 'Python'[2:5] |
tho
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-7-c9c999709965> in <module>
1 s = 'Python'[2:5]
2 print(s)
----> 3 del s[3] # 这一句会报错
TypeError: 'str' object doesn't support item deletion
之前提到过:
字符串常量(String Literal)是不可变有序容器,所以,虽然字符串也有一些 Methods 可用,但那些 Methods 都不改变它们自身,而是在操作后返回一个值给另外一个变量。
而对于列表这种可变容器,我们可以对它进行操作,结果是它本身被改变了。
1 | s = 'Python' |
Python
['P', 'y', 't', 'h', 'o', 'n']
['P', 'y', 'h', 'o', 'n']
列表可用的内建函数
列表和字符串都是容器,它们可使用的内建函数也其实都是一样的:
len()max()min()
1 | import random |
[89, 84, 85]
['X', 'B', 'X']
[89, 84, 85, 'X', 'B', 'X', 89, 84, 85, 89, 84, 85]
[89, 84, 85, 89, 84, 85, 89, 84, 85]
12
X
B
False
Methods
字符串常量和 range() 都是不可变的(Immutable);而列表则是可变类型(Mutable type),所以,它最起码可以被排序 —— 使用 sort() Method:
1 | import random |
a_list comprehends 10 random numbers:
[98, 9, 95, 15, 80, 70, 98, 82, 88, 46]
the list sorted:
[9, 15, 46, 70, 80, 82, 88, 95, 98, 98]
the list sorted reversely:
[98, 98, 95, 88, 82, 80, 70, 46, 15, 9]
如果列表中的元素全都是由字符串构成的,当然也可以排序:
1 | import random |
a_list comprehends 10 random string elements:
['B', 'U', 'H', 'D', 'C', 'V', 'V', 'Q', 'U', 'P']
the list sorted:
['B', 'C', 'D', 'H', 'P', 'Q', 'U', 'U', 'V', 'V']
the list sorted reversely:
['V', 'V', 'U', 'U', 'Q', 'P', 'H', 'D', 'C', 'B']
b_list comprehends 10 random string elements:
['Nl', 'Mh', 'Ta', 'By', 'Ul', 'Nc', 'Gu', 'Rp', 'Pv', 'Bu']
the sorted:
['Bu', 'By', 'Gu', 'Mh', 'Nc', 'Nl', 'Pv', 'Rp', 'Ta', 'Ul']
the sorted reversely:
['Ul', 'Ta', 'Rp', 'Pv', 'Nl', 'Nc', 'Mh', 'Gu', 'By', 'Bu']
注意:不能乱比较…… 被比较的元素应该是同一类型 —— 所以,不是由同一种数据类型元素构成的列表,不能使用 sort() Method。下面的代码会报错:
1 | a_list = [1, 'a', 'c'] |
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-12-acb9480a455d> in <module>
1 a_list = [1, 'a', 'c']
----> 2 a_list = a_list.sort() # 这一句会报错
TypeError: '<' not supported between instances of 'str' and 'int'
可变序列还有一系列可用的 Methods:a.append(),a.clear(),a.copy(),a.extend(t),a.insert(i,x),a.pop([i]),a.remove(x),a.reverse()……
1 | import random |
[90, 88, 73]
[90, 88, 73, 'T', 'N', 'Y', 90, 88, 73, 90, 88, 73]
[90, 88, 73, 'T', 'N', 'Y', 90, 88, 73, 90, 88, 73, '100']
[90, 88, 73]
[]
[90, 88, 73, 'T', 'N', 'Y', 90, 88, 73, 90, 88, 73, '100']
[90, 88, 73, 'T', 'N', 'Y', 73, 90, 88, 73, '100']
[90, 88, 73, 'T', 'N', 'Y', 90, 88, 73, 90, 88, 73, '100']
[90, 88, 73, 'T', 'N', 'Y', 88, 73, '100']
[90, 88, 73, 'T', 'N', 'Y', 88, 73, '100']
[]
[90, 88, 73, 'T', 'N', 'Y', 90, 88, 73, 90, 88, 73, '100']
[90, 88, 73, 'T', 'N', 'Y', 90, 88, 73, 90, 88, 73, '100']
[90, 'example', 88, 'example', 73, 'T', 'N', 'Y', 90, 88, 73, 90, 88, 73, '100']
[90, 'example', 88, 'example', 73, 'T', 'N', 'Y', 90, 88, 73, 90, 88, 73, '100']
['100', 73, 88, 90, 73, 88, 90, 'Y', 'N', 'T', 73, 'example', 88, 'example', 90]
None
有一个命令、两个 Methods 与删除单个元素相关联,del,a.pop([i]),a.remove(x),请注意它们之间的区别。
1 | import random |
[88, 84, 69]
[88, 'example', 84, 69]
[88, 84, 69]
[88, 84, 69]
[88, 84]
69
[88, 84, 'example', 'example']
[88, 84, 'example']
None
[88, 84]
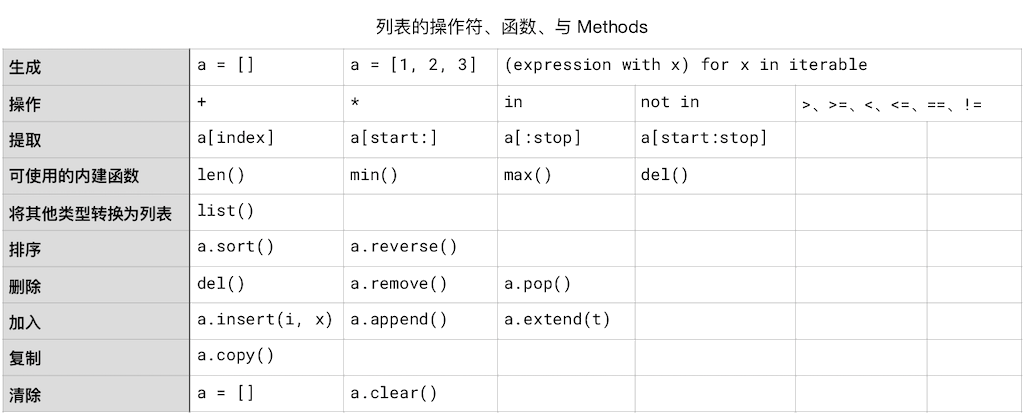
小结
看起来是个新概念,例子全部读完也很是要花上一段时间,然而,从操作上来看,操作列表和操作字符串的差异并不大,重点在于一个是 Immutable,另外一个是 Mutable,所以,例如像 a.sort(),a.remove() 这样的事,列表能做,字符串不能做 —— 字符串也可以排序,但那是排序之后返回给另外一个变量;而列表可以直接改变自身……
而整理成表格之后呢,理解与记忆真的是零压力:
元组(Tuple)
在完整掌握列表的创建与操作之后,再理解元组(Tuple)就容易了,因为它们之间的主要区别只有两个:
- List 是可变有序容器,Tuple 是不可变有序容器。
- List 用方括号标识
[],Tuple 用圆括号 标识()。
创建一个元组的时候,用圆括号:
1 | a = () |
这样就创建了一个空元组。
多个元素之间,用 , 分离。
创建一个含多个元素的元组,可以省略这个括号。
1 | a = 1, 2, 3 # 不建议这种写法 |
(1, 2, 3)
(1, 2, 3)
True
注意:创建单个元素的元组,无论是否使用圆括号,在那唯一的元素后面一定要补上一个逗号 ,:
1 | from IPython.core.interactiveshell import InteractiveShell |
(2,)
2
2
int
(2,)
True
元组是不可变序列,所以,你没办法从里面删除元素。
但是,你可以在末尾追加元素。所以,严格意义上,对元组来讲,“不可变” 的意思是说,“当前已有部分不可变”……
1 | a = 1, |
(1,)
4593032496
(1, 3, 5)
4592468976
初学者总是很好奇 List 和 Tuple 的区别。首先是使用场景,在将来需要更改的时候,创建 List
;在将来不需要更改的时候,创建 Tuple。其次,从计算机的角度来看,Tuple 相对于 List 占用更小的内存。
1 | from IPython.core.interactiveshell import InteractiveShell |
48
80024
90088
等你了解了 Tuple 的标注方式,你就会发现,range() 函数返回的等差数列就是一个 Tuple —— range(6) 就相当于 (0, 1, 2, 3, 4, 5)。
集合(Set)
集合(Set)这个容器类型与列表不同的地方在于,首先它不包含重合元素,其次它是无序的;进而,集合又分为两种,Set,可变的,Frozen Set,不可变的。
创建一个集合,用花括号 {} 把元素括起来,用 , 把元素隔开:
1 | primes = {2, 3, 5, 7, 11, 13, 17} |
{2, 3, 5, 7, 11, 13, 17}
创建
注意:创建空集合的时候,必须用 set(),而不能用 {}:
1 | from IPython.core.interactiveshell import InteractiveShell |
dict
set
也可以将序列数据转换(Casting)为集合。转换后,返回的是一个已去重的集合。
1 | from IPython.core.interactiveshell import InteractiveShell |
{'a', 'b', 'c', 'd', 'e', 'f'}
{0, 1, 2, 3, 4, 5, 6, 7, 8, 9}
{1, 2, 3}
{'a', 'b', 'e'}
Set 当然也可以进行 Comprehension:
1 | a = "abcabcdeabcdbcdef" |
{'d', 'e', 'f'}
操作
将序列类型数据转换成 Set,就等于去重。当然,也可以用 in 来判断某个元素是否属于这个集合。len()、max()、min(),也都可以用来操作 Set,但 del 却不行 —— 因为 Set 中的元素没有索引(它不是有序容器)。从 Set 里删除元素,得用 set.remove(elem);而 Frozen Set 是不可变的,所以不能用 set.remove(elem) 操作。
对于集合,有相应的操作符可以对它们进行集合运算:
- 并集:
|- 交集:
&- 差集:
-- 对称差集:
^
之前用 set('abcabcdeabcdbcdef') 作为简单例子还凑合能用;但这样对读者无意义的集合,无助于进一步的理解。
事实上,每种数据结构(Data Structures —— 在这一章里,我们一直用的概念是 “容器”,其实是指同一事物的两种称呼)都有自己的应用场景。比如,当我们需要管理很多用户时,集合就可以派上很大用场。
假定两个集合中有些人是 admins,有些人是 moderators:
1 | admins = {'Moose', 'Joker', 'Joker'} |
那么:
1 | admins = {'Moose', 'Joker', 'Joker'} |
{'Joker', 'Moose'}
True
False
{'Ann', 'Chris', 'Jane', 'Joker', 'Moose', 'Zero'}
{'Moose'}
{'Joker'}
{'Ann', 'Chris', 'Jane', 'Joker', 'Zero'}
1 | # 这个 cell 集合运算图示需要安装 matplotlib 和 matplotlib-venn |

以上的操作符,都有另外一个版本,即,用 Set 这个类的 Methods 完成。
| 意义 | 操作符 | Methods | Methods 相当于 |
|---|---|---|---|
| 并集 | | |
set.union(*others) |
set | other | ... |
| 交集 | & |
set.intersection(*others) |
set & other & ... |
| 差集 | - |
set.difference(*others) |
set - other - ... |
| 对称差集 | ^ |
set.symmetric_difference(other) |
set ^ other |
注意,并集、交集、差集的 Methods,可以接收多个集合作为参数 (*other),但对称差集 Method 只接收一个参数 (other)。
对于集合,推荐更多使用 Methods 而不是操作符的主要原因是:更易读 —— 对人来说,因为有意义、有用处的代码终将需要人去维护。
1 | from IPython.core.interactiveshell import InteractiveShell |
{'Chris', 'Jane', 'Joker', 'Moose', 'Zero'}
{'Moose'}
{'Joker'}
{'Chris', 'Jane', 'Joker', 'Zero'}
逻辑运算
两个集合之间可以进行逻辑比较,返回布尔值。
set == other
True: set 与 other 相同
set != other
True: set 与 other 不同
isdisjoint(other)
True: set 与 other 非重合;即,set & other == None
issubset(other),set <= other
True: set 是 other 的子集
set < other
True: set 是 other 的真子集,相当于set <= other && set != other
issuperset(other),set >= other
True: set 是 other 的超集
set > other
True: set 是 other 的真超集,相当于set >= other && set != other
更新
对于集合,有以下更新它自身的 Method:
add(elem)
把 elem 加入集合
remove(elem)
从集合中删除 elem;如果集合中不包含该 elem,会产生 KeyError 错误。
discard(elem)
如果该元素存在于集合中,删除它。
pop(elem)
从集合中删除 elem,并返回 elem 的值,针对空集合做此操作会产生 KeyError 错误。
clear()
从集合中删除所有元素。
set.update(*others),相当于 set |= other | ...
更新 set, 加入 others 中的所有元素;
set.intersection_update(*others),相当于 set &= other & ...
更新 set, 保留同时存在于 set 和所有 others 之中的元素;
set.difference_update(*others),相当于 set -= other | ...
更新 set, 删除所有在 others 中存在的元素;
set.symmetric_difference_update(other),相当于 set ^= other
更新 set, 只保留存在于 set 或 other 中的元素,但不保留同时存在于 set 和 other 中的元素;注意,该 Method 只接收一个参数。
冻结集合
还有一种集合,叫做冻结集合(Frozen Set),Frozen Set 之于 Set,正如 Tuple 之于 List,前者是不可变容器(Immutable),后者是可变容器(Mutable),无非是为了节省内存使用而设计的类别。
有空去看看这个链接就可以了:
字典(Dictionary)
Map 是容器中的单独一类,映射(Map)容器。映射容器只有一种,叫做字典(Dictionary)。先看一个例子:
1 | phonebook = {'ann':6575, 'bob':8982, 'joe':2598, 'zoe':1225} |
字典里的每个元素,由两部分组成,_key_(键)和 _value_(值),二者由一个冒号连接。
比如,'ann':6575 这个字典元素,key 是 'ann',value 是 6575。
字典直接使用 key 作为索引,并映射到与它匹配的 _value_:
1 | phonebook = {'ann':6575, 'bob':8982, 'joe':2598, 'zoe':1225} |
8982
在同一个字典里,key 都是唯一的。当创建字典的时候,如果其中有重复的 key 的话,就跟 Set 那样会 “自动去重” —— 保留的是众多重复的 key 中的最后一个 _key:value_(或者说,最后一个 key:value “之前那个 key 的 value 被更新了”)。字典这个数据类型之所以叫做 Map(映射),是因为字典里的 key 都映射且只映射一个对应的 _value_。
1 | phonebook = {'ann':6575, 'bob':8982, 'joe':2598, 'zoe':1225, 'ann':6585} |
{'ann': 6585, 'bob': 8982, 'joe': 2598, 'zoe': 1225}
在已经了解如何操作列表之后,再去理解字典的操作,其实没什么难度,无非就是字典多了几个 Methods。
提蓄一下自己的耐心,把下面的若干行代码都仔细阅读一下,猜一猜输出结果都是什么?
字典的生成
1 | from IPython.core.interactiveshell import InteractiveShell |
{}
{'a': 1, 'b': 2, 'c': 3}
更新某个元素
1 | from IPython.core.interactiveshell import InteractiveShell |
2598
{'ann': 6585, 'bob': 8982, 'joe': 5802, 'zoe': 1225}
5802
添加元素
1 | from IPython.core.interactiveshell import InteractiveShell |
{'ann': 6585,
'bob': 8982,
'joe': 2598,
'zoe': 1225,
'john': 9876,
'mike': 5603,
'stan': 6898,
'eric': 7898}
删除某个元素
1 | from IPython.core.interactiveshell import InteractiveShell |
{'bob': 8982, 'joe': 2598, 'zoe': 1225}
逻辑操作符
1 | phonebook1 = {'ann':6575, 'bob':8982, 'joe':2598, 'zoe':1225, 'ann':6585} |
True
dict_keys(['ann', 'bob', 'joe', 'zoe'])
False
dict_values([6585, 8982, 2598, 1225])
True
dict_items([('ann', 6585), ('bob', 8982), ('joe', 2598), ('zoe', 1225)])
False
可用来操作的内建函数
1 | from IPython.core.interactiveshell import InteractiveShell |
8
'zoe'
'ann'
['ann', 'bob', 'joe', 'zoe', 'john', 'mike', 'stan', 'eric']
('ann', 'bob', 'joe', 'zoe', 'john', 'mike', 'stan', 'eric')
{'ann', 'bob', 'eric', 'joe', 'john', 'mike', 'stan', 'zoe'}
['ann', 'bob', 'eric', 'joe', 'john', 'mike', 'stan', 'zoe']
['zoe', 'stan', 'mike', 'john', 'joe', 'eric', 'bob', 'ann']
常用 Methods
1 | from IPython.core.interactiveshell import InteractiveShell |
{'john': 9876, 'mike': 5603, 'stan': 6898, 'eric': 7898}
{}
{'john': 9876, 'mike': 5603, 'stan': 6898, 'eric': 7898}
('zoe', 1225)
{'ann': 6585, 'bob': 8982, 'joe': 2598}
3538
{'ann': 6585, 'bob': 8982, 'joe': 2598}
3538
{'ann': 6585, 'bob': 8982, 'joe': 2598}
3538
{'ann': 6585, 'bob': 8982, 'joe': 2598, 'adam': 3538}
迭代各种容器中的元素
我们总是有这样的需求:对容器中的元素逐一进行处理(运算)。这样的时候,我们就用 for 循环去迭代它们。
对于迭代 range() 和 list 中的元素我们已经很习惯了:
1 | for i in range(3): |
0
1
2
1 | for i in [1, 2, 3]: |
1
2
3
迭代的同时获取索引
有时,我们想同时得到有序容器中的元素及其索引,那么可以调用 enumerate() 函数来帮我们:
1 | s = 'Python' |
0 P
1 y
2 t
3 h
4 o
5 n
1 | for i, v in enumerate(range(3)): |
0 0
1 1
2 2
1 | L = ['ann', 'bob', 'joe', 'john', 'mike'] |
0 ann
1 bob
2 joe
3 john
4 mike
1 | t = ('ann', 'bob', 'joe', 'john', 'mike') |
0 ann
1 bob
2 joe
3 john
4 mike
迭代前排序
可以用 sorted() 和 reversed() 在迭代前先排好序:
1 | t = ('bob', 'ann', 'john', 'mike', 'joe') |
0 ann
1 bob
2 joe
3 john
4 mike
1 | t = ('bob', 'ann', 'john', 'mike', 'joe') |
0 mike
1 john
2 joe
3 bob
4 ann
1 | t = ('bob', 'ann', 'john', 'mike', 'joe') |
0 joe
1 mike
2 john
3 ann
4 bob
同时迭代多个容器
可以在 zip() 这个函数的帮助下,同时迭代两个或者两个以上的容器中的元素(这样做的前提是,多个容器中的元素数量最好相同):
1 | chars = 'abcdefghijklmnopqrstuvwxyz' |
Let's assume a represents 1.
Let's assume b represents 2.
Let's assume c represents 3.
Let's assume d represents 4.
Let's assume e represents 5.
Let's assume f represents 6.
Let's assume g represents 7.
Let's assume h represents 8.
Let's assume i represents 9.
Let's assume j represents 10.
Let's assume k represents 11.
Let's assume l represents 12.
Let's assume m represents 13.
Let's assume n represents 14.
Let's assume o represents 15.
Let's assume p represents 16.
Let's assume q represents 17.
Let's assume r represents 18.
Let's assume s represents 19.
Let's assume t represents 20.
Let's assume u represents 21.
Let's assume v represents 22.
Let's assume w represents 23.
Let's assume x represents 24.
Let's assume y represents 25.
Let's assume z represents 26.
迭代字典中的元素
1 | phonebook1 = {'ann':6575, 'bob':8982, 'joe':2598, 'zoe':1225, 'ann':6585} |
ann 6585
bob 8982
joe 2598
zoe 1225
1 | phonebook1 = {'ann':6575, 'bob':8982, 'joe':2598, 'zoe':1225, 'ann':6585} |
ann 6585
bob 8982
joe 2598
zoe 1225
总结
这一章的内容,只不过是 “多” 而已,一旦逻辑关系理顺,就会觉得很简单。而这一章的开头,已经是最好的总结了。
最后需要补充的,只是两个参考链接,以后有什么搞不明白的地方,去那里翻翻就能找到答案: